Why Nations Cannot Afford to Leave Artificial Intelligence in Private Hands
Executive Summary
Artificial intelligence has crossed a threshold. It is no longer a commercial technology competing for market share. It is critical national infrastructure, embedded in healthcare systems, financial services, defense procurement, and government operations across allied nations. And yet the governance frameworks applied to it remain those of an early-stage commercial technology: voluntary, fragmented, and entirely dependent on the continued goodwill of a small number of private individuals.
This industry brief argues that governments and multi-state entities must establish sovereign AI frameworks with urgency. The case is not ideological. It rests on three converging realities.
The first is geopolitical sovereignty. Allied governments have allowed themselves to become operationally dependent on AI systems controlled by companies subject to the policy preferences of a foreign executive branch and the governance decisions of individual chief executives. Events in February and March 2026, in which the United States government banned a leading AI provider from all federal use within hours of a contractual dispute, and a rival provider immediately moved to fill that gap on different terms, demonstrated with clarity that governments depending on these systems had no seat at any table where those decisions were made.
The second is systemic risk. The conditions that characterized systemically important financial institutions in 2008 are now present in the AI sector: critical function concentrated in a small number of private entities, asymmetric risk distribution, and governance frameworks built for normal commercial conditions rather than systemic stress. The financial crisis established that the absence of sovereign continuity frameworks does not prevent catastrophic outcomes; it simply ensures that governments bear the cost of them without having shaped the conditions that produced them.
The third is the demonstrated pattern at the software infrastructure layer. The GSDRF’s primary research into open-source software sustainability has documented, with empirical rigor, the consequences of critical software infrastructure being left without sovereign continuity frameworks. The AI governance argument is that same argument applied one layer above, at higher stakes.
The central policy recommendation of this paper is not nationalization of the AI industry. It is the establishment of continuity obligations, accountability frameworks, and independent oversight structures commensurate with the systemic importance AI infrastructure has already acquired. The ownership question is a longer-term policy matter that legislators must begin examining. The continuity question is immediate.
For industry, the message is direct: sovereign AI frameworks are not a distant possibility. The EU AI Act is already in force. Regulatory postures are hardening across the UK, Australia, and New Zealand. The window for constructive engagement in shaping these frameworks is open now. It will not remain so indefinitely.
Section 1: The Geopolitical Sovereignty Case
1.1 The Dependency Problem
Allied governments, public institutions, and critical infrastructure operators have, over the past several years, embedded AI systems from a small number of US-based private companies into their operations at a pace that has significantly outrun the development of any corresponding governance framework. That dependency is now structural.
Those companies are subject to the governance decisions of individual chief executives. They are incorporated under US law, subject to the policy preferences and executive authority of the US government, and under no obligation, legal or otherwise, to consult with, notify, or consider the interests of the governments and institutions in other jurisdictions that have come to depend on their systems.
This is not a theoretical future risk. It is the present reality, and it became undeniable in the last days of February 2026.
1.2 The Anthropic-Pentagon Dispute: A Case Study in Sovereign Exposure
The dispute between Anthropic and the United States Department of Defense that culminated in late February 2026 is the most instructive case study in sovereign AI risk that has yet occurred. It warrants examination in detail, because its implications extend far beyond its immediate parties.
Anthropic, the developer of the Claude AI system, held a contract with the US Defense Department worth up to $200 million, under which Claude had become the first AI system deployed in the military’s classified network. The company had placed two restrictions on the use of its model: it could not be used for mass surveillance of American citizens, and it could not be used to power fully autonomous weapons systems. Anthropic’s position was that these restrictions reflected both the current technical limitations of AI and its own ethical commitments regarding the safe deployment of frontier models.
On 24 February 2026, Defense Secretary Pete Hegseth issued Anthropic CEO Dario Amodei a deadline: remove all restrictions by 5:01pm on 27 February, or face the cancellation of the contract and designation as a supply chain risk to national security. Anthropic refused. On 27 February, President Trump ordered every US government agency to immediately cease using Anthropic’s technology. Hegseth designated the company a supply chain risk, a classification normally reserved for companies associated with foreign adversaries. The designation had the practical effect of threatening the viability of Anthropic’s entire enterprise customer base, many of whose clients hold or seek government contracts.
The Pentagon’s threats were, as Amodei noted, inherently contradictory: one labelled Anthropic a security risk, the other labelled Claude as essential to national security. The contradiction is itself instructive. A system deemed essential to national security was subject to being withdrawn from service within hours by a single executive decision, with no notice to and no consultation with any allied government or institution that had itself come to depend on it.
Anthropic subsequently sued the Department of Defense on 9 March 2026, arguing that the supply chain risk designation was unprecedented, unlawful, and had caused the company irreparable harm. The litigation is ongoing. Talks between the company and the Pentagon have, at the time of writing, partially resumed.
It is important to be clear about what this case illustrates for governments outside the United States. The dispute was between an AI company and the US government, argued on American legal and constitutional grounds, resolved by American political and commercial pressures. No government in Europe, no institution in Australia or New Zealand, no NATO ally that had integrated Claude into any part of its operations, had any standing in those negotiations, any advance notice of the outcome, or any remediation framework prepared for the scenario in which the system they depended on was abruptly withdrawn from service.
That is the exposure. Not that Anthropic acted wrongly. On the assessment of this paper, Anthropic’s ethical position was defensible and its refusal to permit use for mass surveillance and autonomous weapons was reasonable. The point is that the entire determination of whether allied governments retained access to a piece of critical infrastructure was made without them, by people with no accountability to them, under pressure that had nothing to do with their interests.
1.3 The OpenAI Parallel: The Whims of CEOs Cut Both Ways
Within hours of the Trump administration’s ban on Anthropic, OpenAI announced that it had reached a deal with the Pentagon to provide its technology for classified networks. The terms under which OpenAI agreed to operate, as reported at the time, included exclusions preventing use for domestic surveillance or fully autonomous weapons without human approval. In substance, these were not materially different from the position Anthropic had taken.
OpenAI CEO Sam Altman stated publicly that he believed companies should work with the military provided they adhere to legal protections and shared red lines. He framed OpenAI’s position as consistent with Anthropic’s own principles.
The significance of this sequence for the purposes of this paper is not that OpenAI acted opportunistically or that Altman’s position was insincere. It is that, within a single working day, the AI system embedded in allied defense and intelligence infrastructure had changed, the terms under which it was provided had changed, and the company providing it had changed. None of those changes involved any consultation with, approval from, or even notification of the governments and institutions outside the United States that had operational dependencies on these systems.
The lesson is not that AI CEOs are unreliable. Some will hold principled positions under extraordinary pressure, as Amodei did. Others will move more fluidly in response to commercial and political incentives, as the market dynamics of the situation illustrate. The lesson is that the critical infrastructure of sovereign states should not be contingent on the character of any individual chief executive. Character is not a governance framework.
1.4 The Broader Geopolitical Frame
The AI sector has not yet had its Lehman Brothers moment.
The Anthropic-Pentagon dispute is the sharpest available illustration of the problem, but it sits within a much broader geopolitical reality. AI infrastructure concentration is a sovereignty risk for every nation that does not have its own frontier AI capability, and currently that means effectively every nation outside the United States and, to a limited and contested degree, China.
The European Union, the United Kingdom, Australia, and New Zealand are among the jurisdictions most acutely exposed. Each has allowed significant operational dependency on US-based AI systems to develop across government and critical infrastructure. Each is now, in various ways, confronting the implications. The EU’s AI Act represents the most developed legislative response. Regulatory challenges and litigation in Australia and New Zealand signal that those governments are recognizing the power imbalance even if comprehensive remediation frameworks remain nascent.
The direction of travel is clear. What is less clear is whether governments will move proactively to establish sovereign frameworks before the next systemic disruption, or reactively in response to one. The financial crisis precedent, examined in the following section, suggests that reactive responses are both more expensive and less effective than proactive frameworks. The AI sector has not yet had its Lehman Brothers moment. That is not an argument for complacency. It is an argument for acting while the window remains open.
Section 2: The Systemic Risk Case
2.1 Too Big to Fail: The Financial Crisis as a Governance Template
The phrase ‘too big to fail’ entered the policy lexicon in the context of the 2008 global financial crisis. Its meaning, stripped of the political controversy that surrounded it, was precise: certain institutions had become so embedded in the functioning of the broader financial system that their disorderly failure would produce consequences disproportionate to their own commercial significance. The systemic damage would be borne not by the institutions themselves, or their shareholders, but by governments and the populations they serve.
The conditions that produced that outcome are now recognizable in the AI sector. A small number of private entities control systems of critical importance to multiple governments and economic sectors. The benefits of those systems accrue privately. The catastrophic downside risk, the scenario in which access is abruptly lost, terms are unilaterally changed, or a provider fails commercially, is borne collectively by the governments and institutions that have allowed the dependency to develop.
The financial crisis also established a second lesson that is directly applicable here. The absence of sovereign continuity frameworks does not prevent catastrophic outcomes. It simply ensures that when those outcomes occur, governments must respond under maximum pressure, with minimum preparation, at maximum cost. The ad hoc interventions of 2008, the emergency bailouts, the improvised resolution mechanisms, the political contortions required to justify spending public money to rescue private institutions, were the direct consequence of governance frameworks that had not kept pace with the systemic importance of the institutions they were supposed to oversee.
The Lehman Brothers parallel is worth stating directly. In a scenario where a major AI provider faces abrupt commercial failure, is sanctioned by a foreign government, or is subjected to the kind of designation that the Trump administration applied to Anthropic, the governments depending on that provider’s systems face a choice between a managed transition, if continuity frameworks exist, and an emergency scramble, if they do not. The cost of the former is a fraction of the cost of the latter.
2.2 The International Monetary Architecture as Governance Model
The International Monetary Fund, the European Central Bank, and the US Federal Reserve did not come into existence because governments wanted to control their economies. They came into existence because governments recognized that systemically important economic functions required governance structures that were technically credentialed, insulated from short-term political pressure, and empowered to act in the long-term systemic interest rather than the immediate commercial or electoral one.
The central bank independence model is the most relevant template for sovereign AI governance, and for a reason that goes beyond structural analogy. Central bank independence was designed specifically to address the problem of technically complex, systemically critical functions being governed by institutions subject to the short-term incentives of elected officials or private market participants. Neither elected officials nor private market participants are well-positioned to make governance decisions about systemically critical AI infrastructure. The same logic that produced central bank independence produces the case for an Independent AI Oversight Council.
Such a body would not build AI systems. It would not direct their development. It would do what central banks do: establish and enforce the systemic stability conditions under which AI infrastructure can operate safely. In practical terms, this means continuity obligations, mandatory transition planning, transparency and reporting requirements, and the authority to intervene when those obligations are not met.
The institutional form matters. A body that reports to elected governments is subject to the same political pressures that make elected governments poor governors of technically complex systemic risk. The ECB model, with a defined and limited mandate, technical independence, and democratic accountability through transparency and reporting rather than direct political control, is the appropriate template.
2.3 The Spectrum of Sovereign Intervention
There is an important distinction to draw, both analytically and politically, between the different forms sovereign intervention in the AI sector might take. Conflating them weakens the argument and obscures the range of achievable policy options.
At one end of the spectrum is full state ownership: a government acquires an AI company outright, as it might acquire a failing bank or a strategic energy asset. This is not a fantasy position in all jurisdictions. France’s tradition of strategic state ownership, Germany’s willingness to take equity stakes in critical industries, and the EU’s capacity to mandate structural remedies under competition law all create contexts in which ownership is a credible policy instrument. For most Western democracies, however, full state ownership of commercial AI companies is politically and practically difficult as a default position, and this paper does not advocate for it as such.
At the other end of the spectrum is mandatory continuity infrastructure: AI companies operating in critical sectors are required to maintain model escrow arrangements, transition plans, and structured access agreements that allow governments to manage a change of provider without operational disruption. This is analogous to the bank resolution planning requirements introduced after 2008, under which systemically important financial institutions are required to maintain ‘living wills’ detailing how they could be wound down in an orderly fashion. It is achievable, bounded, and politically defensible.
Between these poles lies a range of intermediate options: mandatory licensing regimes, state-backed continuity funds, equity participation requirements, and structured access agreements with allied governments. The appropriate instrument will vary by jurisdiction, sector, and the specific nature of the AI dependency in question.
The central argument of this paper is for the continuity infrastructure end of this spectrum as the immediate and achievable policy ask, with state ownership acknowledged as the backstop option that legislators in appropriate jurisdictions should begin examining. Continuity infrastructure is not a compromise position. It is the foundational governance requirement without which all other policy options are moot.
Section 3: The Open-Source Software Continuity Bridge
3.1 The Pattern Established at the Infrastructure Layer
The argument for sovereign AI governance does not exist in isolation. It is the continuation of a pattern that the GSDRF’s primary research has documented with empirical rigour at the software infrastructure layer on which AI systems are built.
The GSDRF’s analysis of GHArchive data covering the period 2015 to 2025, drawn from original BigQuery primary research, has established several findings directly relevant to this argument. Open-source software project health showed a COVID-period bounce followed by an incomplete recovery. From 2023 onward, a divergence between event activity and contributor activity emerged, consistent with AI-generated noise inflating apparent activity while genuine human contributor engagement declined. From 2024 into 2025, the decline in established OSS projects accelerated sharply.
Crucially, the research identified a clear bifurcation in outcomes. Projects with profit-motivated institutional investment behind them, such as VS Code, Hugging Face Transformers, and NixOS, sustained their contributor ecosystems. Projects with extractively-backed or commercially indifferent support structures collapsed. The determining variable was not the technical quality of the project or its importance to the broader ecosystem. It was whether a sustained institutional commitment to its continuity existed.
3.2 The Sovereign OSS Fund as Proof of Concept
The GSDRF has separately developed the case for a Sovereign OSS Fund, structured around mandatory contributions scaled to deployment intensity and governed by an Independent Review Council modelled on central bank independence. The argument rests on precisely the same logic that this paper applies to the AI layer: critical infrastructure that is systemically important but commercially fragile requires sovereign continuity frameworks to protect against the consequences of its failure.
The Sovereign OSS Fund proposal is therefore not merely analogous to the sovereign AI governance argument. It is its direct predecessor. If the case for sovereign intervention holds at the OSS infrastructure layer, the same argument applied to the AI systems built on top of that layer is not a radical extension of principle. It is the consistent application of a framework that has already been established.
For policymakers and legislators examining sovereign AI governance proposals, the OSS fund model provides a working template. It demonstrates that the governance instruments required are not novel. They exist in adjacent policy domains and have been developed with the specific characteristics of software infrastructure in mind.
3.3 The Compounding Risk
The interaction between OSS decline and AI dependency is not additive. It is multiplicative. AI systems are, in significant part, built on OSS foundations. The models, the training infrastructure, the deployment tooling, the security frameworks, all have substantial open-source components. As OSS project health at the foundation layer degrades, the AI systems built on it become less reliable, less secure, and more dependent on the continued commitment of the small number of well-capitalised institutions that are sustaining those foundational projects.
A sovereign AI governance framework that does not address the OSS layer is therefore incomplete. And an OSS continuity framework that does not extend its logic to the AI layer built on top of it is addressing the foundation while ignoring the structure. A coherent sovereign technology policy must address both layers as a connected system, or it addresses neither adequately.
Section 4: A Policy Framework for Sovereign AI
4.1 Core Principles
Any credible sovereign AI governance framework must rest on four core principles if it is to be both effective and politically sustainable.
The first is proportionality. Governance obligations should be scaled to systemic importance. AI systems embedded in critical national infrastructure carry different obligations than AI systems used in commercial applications. The framework should be tiered accordingly.
The second is technical independence. The governance body must be insulated from both short-term political pressure and commercial influence. This is the central lesson of the central bank independence model. Credibility depends on it.
The third is continuity primacy. The foundational obligation is continuity of access: the assurance that a government or institution depending on an AI system can manage a change of provider, or a disruption to service, without operational catastrophe. All other governance obligations flow from this.
The fourth is international co-ordination. AI infrastructure is global. Fragmented national frameworks create regulatory arbitrage and reduce effectiveness. The EU’s demonstrated capacity to export regulatory standards through market access leverage provides the most credible vehicle for international co-ordination, and should be the anchor of any multilateral sovereign AI governance effort.
4.2 The Tiered Intervention Model
Sovereign AI governance should operate across a defined spectrum of intervention levels, with the appropriate level determined by the systemic importance of the AI deployment in question.
Tier 1: Mandatory Continuity Infrastructure. All AI systems deployed in critical national infrastructure must maintain model escrow arrangements, transition plans, and structured access agreements. This is the minimum viable sovereign governance requirement and the immediate policy ask of this paper. It is analogous to bank resolution planning and is achievable through existing legislative mechanisms in most jurisdictions.
Tier 2: Independent Oversight Accountability. AI systems of defined systemic importance must report to an Independent AI Oversight Council on continuity, security, and transparency obligations. The Council’s mandate is defined and limited; it does not direct development but enforces the systemic stability conditions under which AI infrastructure operates.
Tier 3: Structured Access and Licensing. For AI systems of the highest systemic importance, mandatory licensing regimes and structured access agreements with participating governments provide additional resilience. State-backed continuity funds, modelled on the Sovereign OSS Fund architecture, provide a financial backstop.
Tier 4: State Participation and Ownership. In scenarios where a provider of critical AI infrastructure faces commercial failure or is otherwise unable to meet its continuity obligations, state ownership or equity participation is the backstop of last resort. Legislators in appropriate jurisdictions should develop the legal and financial frameworks for this option before it is needed, not in response to a crisis.
4.3 The Jurisdictional Opportunity: EU Leadership and Multilateral Co-ordination
The European Union is the most credible anchor for a multilateral sovereign AI governance framework, for reasons that are structural rather than aspirational. The EU has demonstrated, through GDPR and now the AI Act, that it can export regulatory standards globally by virtue of market access leverage. Companies operating in EU markets must comply with EU frameworks regardless of where they are incorporated. That leverage is real, has been tested, and has proven effective.
The EU AI Act, already in force with phased implementation obligations, establishes the foundational regulatory architecture on which a sovereign AI governance layer can be built. It addresses risk classification and prohibitions. What it does not yet fully address is continuity infrastructure and systemic risk governance of the kind this paper advocates. The extension of the AI Act framework to incorporate the continuity obligations described above is both legally achievable and politically consistent with the EU’s established regulatory posture.
The United Kingdom, post-Brexit, has both the incentive and the regulatory capability to develop a complementary framework rather than a derivative one. A UK-EU co-ordination mechanism on AI governance continuity standards would extend the reach of both frameworks and reduce the regulatory arbitrage risk that fragmentation creates.
Australia and New Zealand’s active and increasingly assertive regulatory posture towards large technology platforms, as evidenced by Australia’s News Media Bargaining Code and subsequent legislative interventions, signals political readiness for the kind of sovereign AI governance framework this paper describes. Their participation in a multilateral co-ordination mechanism anchored by the EU and UK would significantly extend its geographic reach and credibility.
4.4 Timeline: This Is a Two to Three Year Question
The framing of sovereign AI governance as a future policy concern is no longer accurate. It is a present policy urgency.
The EU AI Act is in force. High-risk AI system obligations are phasing in. The regulatory architecture exists. The question is whether the continuity infrastructure layer is added to it through deliberate legislative action or whether it is constructed reactively in response to the first major AI continuity failure.
The UK’s post-Brexit regulatory agenda includes AI governance as a priority. The institutional capability exists. The political will is developing. The window for proactive framework design is open now.
Australia and New Zealand have demonstrated that they are willing to move decisively when they perceive a structural power imbalance between large technology platforms and the public interest. The Anthropic-Pentagon dispute will not have gone unnoticed in those jurisdictions.
Industry and public sector decision makers who are treating sovereign AI governance as a five to ten year horizon question are misreading the pace of regulatory development. The more realistic planning horizon is two to three years for initial legislative frameworks in leading jurisdictions, with compliance obligations following within the standard implementation period thereafter.
Section 5: A Briefing for Industry
5.1 The Honest Assessment
This section speaks directly to industry leaders in the AI sector and in the enterprise organisations that depend on AI infrastructure. The message is not adversarial. It is practical.
Sovereign AI frameworks are coming. The political conditions that produced the EU AI Act, the regulatory assertiveness of Australia and the UK, and the object lesson of the Anthropic-Pentagon dispute have created a political environment in which legislative action on AI governance continuity is not a possibility but a matter of timing. The question for industry is not whether these frameworks will exist, but whether the industry will have shaped them or been subjected to the version written without its input.
The history of technology regulation does not favour the second option. GDPR was written largely without meaningful industry co-design. The compliance costs, the legal uncertainty, and the regulatory friction that followed were, in significant part, the consequences of that absence. The AI Act, developed over several years with extensive consultation, is materially better calibrated. The lesson is available to be learned.
5.2 Why Well-Designed Sovereign Frameworks Serve Industry Interests
The reflexive industry objection to sovereign AI governance frameworks is that they chill innovation, create bureaucratic overhead, and reduce competitive agility. This objection has surface plausibility and limited analytical depth.
Regulatory clarity reduces uncertainty. The single greatest cost of the current unregulated environment is not compliance overhead. It is the uncertainty premium that enterprise customers, institutional investors, and government procurement officials apply when they cannot assess the governance risk of the AI systems they are considering deploying. A credible sovereign governance framework, by establishing clear and consistent obligations, reduces that uncertainty premium and expands the addressable market for compliant providers.
Independent oversight reduces litigation risk. The accumulating litigation and regulatory challenge that AI companies face across the EU, Australia, New Zealand, and now in the United States itself is not a temporary feature of an early market. It is the predictable consequence of systemically important technology operating without adequate governance frameworks. A credible independent oversight body reduces the political and legal surface area for that litigation by establishing that governance obligations exist and are being enforced.
Continuity obligations are commercially valuable. Enterprise customers and government procurement officials are increasingly requiring assurance that the AI systems they depend on will remain available, on consistent terms, for the planning horizons they operate across. A provider that can demonstrate credible continuity infrastructure is more attractive than one that cannot, all else being equal. Sovereign governance frameworks, by mandating continuity infrastructure, level the playing field and prevent the race-to-the-bottom dynamics that make continuity assurance commercially difficult to offer unilaterally.
5.3 What Constructive Engagement Looks Like
Constructive engagement with sovereign AI governance framework development is not a public relations exercise. It is a strategic imperative, and it has a specific content.
It means participating actively in legislative consultation processes, with substantive technical input rather than lobbying against the principle of governance. It means proactively developing and publishing continuity infrastructure that demonstrates the industry can meet reasonable sovereign governance expectations without waiting for legislation to mandate it. It means engaging transparently with independent oversight bodies on reporting and accountability obligations rather than treating them as adversarial.
It also means accepting that the era in which individual AI companies could unilaterally determine the terms on which governments and their institutions access critical AI infrastructure is ending. That is not a regulatory overreach. It is the natural and appropriate consequence of AI infrastructure crossing the threshold from commercial technology to critical national infrastructure. The companies that recognise and adapt to that reality will be better positioned in the regulatory environment that is coming than those that contest it.
Conclusion
The argument of this paper is not about whether artificial intelligence is beneficial. It is, in most of its applications, enormously so. It is not about whether the companies developing frontier AI are acting in bad faith. The Anthropic case is instructive here: the company’s refusal to permit its technology to be used for mass surveillance of citizens or to power fully autonomous weapons is not a radical or outlying position. It is entirely consistent with the prohibited use categories established under the EU AI Act, with the stated policies of most allied defense ministries, and with the ethical frameworks that the broader AI industry has itself publicly endorsed. What was unusual in the Anthropic-Pentagon dispute was not Anthropic’s position. It was the US executive branch’s demand that a private company abandon protections that are, by any international standards measure, established norms of responsible AI deployment. That context matters for how industry leaders read the dispute: not as evidence that AI companies are ungovernable, but as evidence that governance frameworks which depend on the alignment of a single national executive with international norms are insufficient protection for anyone.
It is tempting to read the sovereign AI governance argument as primarily a concern for non-American governments and institutions. It is not. American companies operating in sectors with any government adjacency face the same continuity and dependency risks as their international counterparts, in some respects more acutely. The supply chain risk designation applied to Anthropic in February 2026 did not distinguish between European and American enterprise customers. It threatened the operational continuity of any organization, domestic or international, that had integrated Claude into systems touching government work. Those organizations had no advance notice, no seat at the table, and no prepared response. American enterprises are inside the same governance gap as everyone else. In certain scenarios, given their direct and unmediated exposure to domestic executive authority, they are deeper inside it.
This paper is, at its core, about closing that gap. The governance frameworks required are not punitive towards industry, and they are not designed to be. The central bank independence model, the bank resolution planning requirements, the market access leverage mechanisms that underpin EU regulatory standards, the Sovereign OSS Fund architecture: these frameworks exist to create the conditions under which systemically important institutions can operate sustainably, with the confidence of the governments and populations they serve. AI infrastructure has crossed the threshold that makes equivalent frameworks necessary. That is not a judgement on the industry. It is a description of how far it has come.
The events of February and March 2026 have made the cost of that absence visible in a way that is difficult to dismiss. The window for proactive sovereign AI governance frameworks is open. It will not remain so indefinitely, and the frameworks constructed in response to the next major AI continuity failure will be more expensive, less well-designed, and more politically contentious than those built in anticipation of it.
Sovereign AI frameworks are coming, on a two to three year legislative horizon in leading jurisdictions. The companies and institutions that engage constructively now, helping to shape continuity infrastructure that is workable, proportionate, and technically credible, will be better positioned than those that wait. More than that: they will have contributed to a governance environment that is better for the industry as a whole, because it is one that governments and the public can trust. That trust is the condition on which the continued expansion of AI into critical systems depends. It cannot be assumed. It has to be built. Sovereign governance frameworks are how it gets built.
References
The Anthropic–Pentagon Dispute
Axios : Anthropic says Pentagon’s ‘final offer’ is unacceptable (26 February 2026) 🔗
CNN Business : Anthropic rejects latest Pentagon offer (26 February 2026) 🔗
CNN Business : Trump administration orders military contractors and federal agencies to cease business with Anthropic (27 February 2026) 🔗
CNBC : Trump admin blacklists Anthropic as AI firm refuses Pentagon demands (27 February 2026) 🔗
NPR : OpenAI announces Pentagon deal after Trump bans Anthropic (27–28 February 2026) 🔗
CBS News : Anthropic CEO: We’re trying to ‘deescalate’ Pentagon AI standoff (4 March 2026) 🔗
CNN Business : Anthropic sues the Trump administration after it was designated a supply chain risk (9 March 2026) 🔗
Fortune : Anthropic sues the Pentagon after being labeled a threat to national security (9 March 2026) 🔗
The Washington Post : Anthropic sues Pentagon over being labeled a national security risk (9 March 2026) 🔗
Tech Policy Press : A Timeline of the Anthropic–Pentagon Dispute (9 March 2026) 🔗
EU AI Act and Regulatory Framework
European Parliament and Council of the European Union : Regulation (EU) 2024/1689 of the European Parliament and of the Council (Artificial Intelligence Act) (2024) 🔗
European Commission : Guidelines on Prohibited Artificial Intelligence Practices established by Regulation (EU) 2024/1689 (4 February 2025) 🔗
European Parliament : Guidelines for military and non-military use of Artificial Intelligence (2021) 🔗
Tech Policy Press : Europe’s AI Act Leaves a Gap for Military AI Entering Civilian Life (10 March 2026) 🔗
Future of Privacy Forum : Red Lines under the EU AI Act: Understanding Prohibited AI Practices and their Interplay with the GDPR (2025) 🔗
Australia and Platform Regulation
Australian Competition and Consumer Commission : News Media Bargaining Code (2021) 🔗
Parliament of Australia : Treasury Laws Amendment (News Media and Digital Platforms Mandatory Bargaining Code) Act 2021 (2021) 🔗
Bossio, D. et al. : Australia’s News Media Bargaining Code and the global turn towards platform regulation (2022) 🔗
GSDRF Primary Research
Global Software Development Research Foundation (2025–2026). “OSS Sustainability and AI Impact: Primary Research on GHArchive Data 2015–2025.” Original BigQuery analysis. Internal research dataset, GSDRF.
Global Software Development Research Foundation (2025–2026). “Future Proofing Software Development.” GSDRF Policy Paper.
Financial Crisis and Systemic Risk Governance
Financial Stability Board : Reducing the Moral Hazard posed by Systemically Important Financial Institutions (October 2010) 🔗
Basel Committee on Banking Supervision : Global systemically important banks: assessment methodology and the additional loss absorbency requirement (2011) 🔗
Council on Foreign Relations : The Defense Production Act of 1950: History, Authorities, and Considerations for Congress (2020) 🔗
GSDRF Primary Research
Stop Killer Robots Campaign : What are the AI Act and the Council of Europe Convention? (2023) 🔗
Paul Hastings LLP : European Commission & AI: Guidelines on Prohibited Practices (2025) 🔗
Global Software Development Research Foundation | Policy Research | March 2026
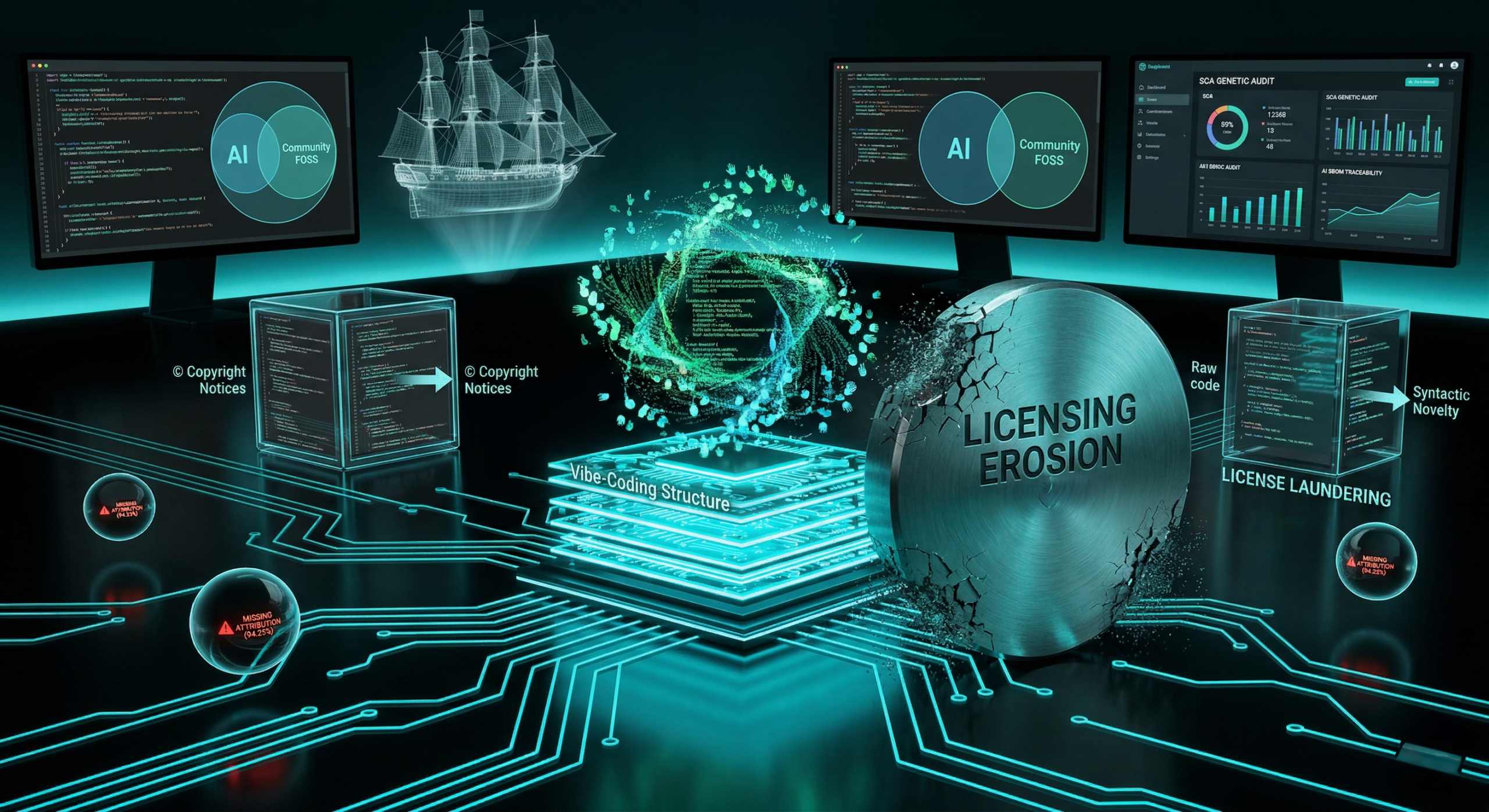
Between “Vibe-coding” and license laundering, generative AI is shaking the very foundations of Open Source. From the Chardet case study to the Ship of Theseus paradox, this is an analysis of an ecosystem where automated rewriting threatens to break the digital social contract and permanently erase the contributor’s footprint.
Executive Brief
The Open Source Era of “Vibe-coding” and License Erosion.
I. Current State: The Breach of the Social Contract
The emergence of Generative AI is transforming software development into a task of supervision rather than writing, a shift captured by the concept of “vibe-coding.” This computational power now allows for the total rewriting of complex libraries in just a few days. It shatters the natural barrier of effort that, until now, protected Copyleft licenses such as the GPL or LGPL.
The Chardet Case Study: A total AI-driven rewrite in five days, followed by a pivot from a strict license to a permissive one (MIT). This effectively removes the obligation to “give back to the community.”
II. Strategic Risks and Threats
AI Washing & License Laundering: Using LLMs as “translation machines” to scrub original legal restrictions under the guise of syntactic novelty.
The “Payload Gap”: A study reveals that 94.25% of AI artifacts omit mandatory copyright notices. This lack of documentation creates an invisible infringement risk for end-user companies.
The Legal Impasse (Thaler v. Perlmutter): Code generated without direct human intervention may belong to the public domain. In a legal absurdity, maintainers are applying licenses to rights they do not theoretically possess.
III. Philosophical Perspective: The Ship of Theseus
The debate is not about syntax, it is about identity. If AI replaces every “part” (the code) but retains the “blueprint” (the logic and function), the work remains a derivative work. To claim otherwise is to validate appropriation without contribution, to the detriment of the original intellectual authorship.
IV. Recommendations for the Enterprise
Radical Provenance Audits: Move beyond surface-level analysis to track the “genetic” origin of the code using next-generation SCA (Software Composition Analysis) tools.
Adopting “AI-Proof” Standards: Support the implementation of AI-specific SBOMs (Software Bill of Materials) to guarantee the traceability of training sources.
Prioritizing “FOSS-respecting” Models: Direct technological choices toward transparent and auditable models. This ensures genuine digital sovereignty and long-term legal security.
Conclusion
AI must not become the enemy of Open Source. The permanence of our collective software heritage depends on our ability to intelligently implement rigorous traceability in the face of automated plagiarism.
The AI Code Laundromat: Introduction
Anyone familiar with the Open Source world will have noticed that Artificial Intelligence is disrupting the serenity and trust that the developer community has long enjoyed. It turns out that AI is becoming an industrial-scale tool for circumventing the licenses that, until now, protected the work of authors. This automation directly clashes with the vision of Linus Torvalds, for whom the strength of Open Source rests on a contract of reciprocity. For him, the right to use the work of others is inseparable from the duty to share one’s own improvements. Using AI to “launder” a license and appropriate logic without giving back to the community breaks the virtuous circle of collaboration that allowed the emergence of our greatest technological standards. Indeed, the arsenal of Gen AI tools unfortunately makes it possible to generate syntactically new versions of source code while preserving its business logic, to the detriment of the original authors and contributors. This intelligent automation undermines the rules and customs of intellectual property. It disrupts the ecosystem from a legal perspective and challenges the very principles of intellectual property.
The Chardet library, an essential encoding detection tool downloaded over 130 million times per month, has become a textbook case in this regard. In just five days, this project was entirely rewritten using the Claude AI. Consequently, the new maintainers took the opportunity to pivot from a strict license (LGPL) to an extremely permissive one (MIT).
To fully grasp the stakes of this legal shift, one must distinguish between the philosophies of these two licenses. The LGPL is a so-called “Copyleft” license that allows the use of code but mandates that any modification or improvement to the library must also be shared under the same license. In contrast, the MIT license is “permissive.” It allows for the reuse, modification, and even integration of the code into closed proprietary software, with the only real obligation being to preserve the original copyright notice. Moving from one to the other effectively removes the obligation to “give back to the community” what was borrowed.
This practice reveals a growing phenomenon known as “AI Washing,” which currently manifests in two distinct ways that are deeply corrosive to the ecosystem. On one hand, there is license laundering, which involves using Large Language Models (LLMs) as literal “translation machines” for code. The goal is to scrub the original legal restrictions under the guise of technical rewriting. On the other hand, we see permissive washing, the deceptive labeling of AI artifacts as “free.” In these cases, models or datasets are presented as “open” even though indispensable legal documents, such as license texts and copyright notices, are entirely missing from the repositories. This lack of a legal payload, the physical absence of the license text within the code or model in favor of a mere label, makes these tools legally toxic for developers and companies. It turns a promise of openness into a true compliance nightmare.
The Technological Aspect
For a new generation of technicians, Generative AI can seem like a magic wand capable of liquidating years of technical debt in record time. We are witnessing the emergence of “vibe-coding.” This is a practice where the developer no longer writes code, but instead supervises the massive and instantaneous production of lines of code by a machine. The Chardet case illustrates this power perfectly. Where a manual refactor would have required months of work, AI made it possible to deliver a version in just a few days, boasting a staggering 48x increase in execution speed.
The technological prowess displayed by AI tools is dissolving the major obstacles that once stood in the way human cost, time, and the intellectual effort required to rewrite complex code. Not long ago, any desire for a total refactor hit the natural wall of the task’s sheer scale. A lack of resources also immediately discouraged any attempt at license circumvention. Today, that barrier has fallen. With AI, the effort required to radically transform a software’s syntax while preserving its underlying logic has become virtually non-existent.
It is necessary to clear up a major misunderstanding to fully grasp what is at stake. AI does not, in any way, perform what could be considered “Clean Room Design.” Historically, this method relied on an absolute wall between two groups of engineers. A “Dirty Room” team would analyze the original code to extract pure functional specifications, while a “Clean Room” team would write the new code based solely on those instructions, without ever having been exposed to a single line of the source software. This procedure was designed to prove in court that any final similarities were the result of technical necessity rather than plagiarism.
However, an LLM is not an isolated entity, as it carries within it the footprint of its training data, which often includes the very source code one is trying to rewrite. When a developer submits a block of code to an AI for improvement, the algorithm invents nothing. In reality, it acts as a high-level translator. The original logic, structure, and inventiveness persist, even if they appear in a new syntactic form. It is clear, then, that AI does not create. In a sense, it camouflages. Ultimately, changing the words is not enough to erase the invention. Under the varnish of a new syntax, the code remains a derivative work that still belongs to its original author.
This technical ease creates a void in terms of traceability. If the prompt used contains all or part of the original source code, the AI technically cannot guarantee that its output is not simply plagiarism by reformulation. For the community, this means a project could appear visually new while being, in reality, a form of automated infringement. Worse still, provenance auditing would become nearly impossible without extremely sophisticated similarity analysis tools. This computational power does not merely serve technical performance. It must be understood as the engine of a deliberate legal circumvention strategy.
Strategic and Economic Drivers of “Laundering”
While switching to a permissive license via AI certainly serves a technical purpose, a closer look reveals it is equally a deliberate strategy to disengage from Copyleft obligations. The primary lever for this practice is the desire to neutralize the recursive nature of Copyleft licenses, which ensure the persistence of authorship rights. For a corporation, restrictive licenses like the GPL are perceived as a heavy burden because they mandate the public release of the source code for any derivative work. By using AI to “wash” the original code and re-license it under MIT or Apache, organizations can bypass this risk. In doing so, they grant themselves permission to privatize entire segments of collective intelligence, appropriating them into proprietary products or SaaS offerings to generate profit without ever having to redistribute their own improvements.
Beyond the commercial stakes, AI offers a really new administrative shortcut. Historically, changing the license of a legacy project required the unanimous consent of every contributor. In practice, this process was often impossible to carry out. Here, the machine allows developers to evade this requirement for consensus through a complete syntactic rewrite. Thus, new maintainers claim to start from a technical “blank slate” to avoid the legal burden of recognizing past authors. This practice makes it possible to resolve technical debt at a negligible cost. As illustrated by Chardet’s spectacular performance leap (recall that its speed increased 48-fold) AI does more than just change a legal label. It makes a full refactor nearly instantaneous. What once required months of manual labor is now liquidated in a matter of days. For Big Tech, the stakes are colossal. The goal is to transform nearly the entire Open Source heritage into a raw data set, stripped of its copyright notices, to fuel proprietary models.
Redefining Intellectual Property
The situation borders on the absurd when these practices are confronted with current case law, specifically the Thaler v. Perlmutter case. In this instance, the United States Copyright Office maintains that works generated without direct human intervention cannot be protected by copyright. This results in a total legal impasse. If AI-produced code belongs to the public domain by default due to the lack of a human author, new maintainers theoretically lack the standing to apply an MIT license to it. We are entering a reality where it becomes possible to grant or restrict rights that one does not technically possess.
Beyond these theoretical debates, the reality on the ground reveals a massive erosion of legal safeguards. A study from Queen’s University highlights an alarming phenomenon where 96.5% of datasets and 95.8% of models labeled as “permissive” omit the mandatory license text. As a reminder, “permissive” refers to licenses (such as MIT or Apache) that allow for broad reuse, including commercial use, with the primary requirement being the obligation to credit the original author and include the license text. Unfortunately, we see here that the law is fading behind a simple marketing metadata tag with no real legal value. For the end user, this “Payload Gap” creates a false sense of security. They believe they are handling an open tool, when in fact they are exposing themselves to infringement risks due to an inability to prove the chain of title.
Toward “AI-Proof” Licenses?
To counter this erosion of legal protections, the open-source community is beginning to build new ramparts capable of restoring a form of legal guarantee. These new types of licenses, dubbed “AI-proof,” aim to close the loopholes exploited by automated laundering.
One of the primary levers is to legally neutralize the “Clean Room” myth. New clauses could explicitly stipulate that any code generated or translated by an AI model exposed to the original source code during its training constitutes, by nature, a derivative work. Such a provision would prohibit the use of an LLM as a mere “syntactic engine” to bypass Copyleft obligations. In this scenario, we would simply restore the legal lineage that the AI sought to erase by linking the output to the training source.
We are witnessing a major strategic shift. This change is significant because the focus is no longer just on who has “the right to copy the code”, but rather on “what they are allowed to do with it”. This is the core purpose of RAIL (Responsible AI Licenses). Unlike traditional licenses that govern how code is copied, RAIL licenses introduce behavioral rules. They impose limits on how the model can be used (for instance, prohibiting surveillance or disinformation) and require these constraints to propagate to all downstream applications. It is a compelling way to regain control over the technology’s ultimate purpose rather than just its text. A technical counter-offensive is also necessary. To combat the “Payload Gap,” traceability standards such as AI-adapted SBOMs (Software Bill of Materials) are currently under development. The goal is to force models to embed an unforgeable digital identity of their sources. In this scenario, a tool’s inability to provide this proof of provenance would render any commercial exploitation of the generated code legally void. In this context, traceability becomes a sine qua non for legality.
Strategic Risks and Shifts for the Enterprise
For decision-makers and legal counsels, integrating AI-“laundered” code is no longer a simple matter of technical monitoring, but a major operational risk. Incorporating a component whose license has been altered by a syntactic engine is equivalent to injecting an invisible vulnerability into the heart of the software supply chain. During a deep audit, such as during a fundraising round, a merger and acquisition (M&A), or an initial public offering (IPO), the inability to prove the legitimacy of a license could invalidate the very value of a technological asset. It is therefore becoming vital to use next-generation Software Composition Analysis (SCA) tools, capable of tracking not just library names, but the “genetic” origin of the code itself. This threat extends beyond the corporate world to touch the very essence of Free Software. According to Bruce Perens, widely regarded as one of the founding fathers of Open Source, this capacity for industrial-scale cloning by AI could well signal the death knell of the current model. In his Keynote “What comes after open source?”, he ironically states: “We’re an excellent welfare program for corporations. Our users are the richest companies in the world.” We must acknowledge that if any actor can appropriate a Copyleft project and “turn” it proprietary by running it through an LLM, then licenses like the GPL lose their protective power. In this case, the social contract ensuring that everything taken from the community must be returned to it literally shatters. Open Source becomes a free reservoir for proprietary software.
Yet, amid this chaos, an opportunity is emerging for the most visionary entrepreneurs. Since they are becoming an abundant commodity, easy to generate, the value of software may no longer reside in the lines of code themselves, but rather in the quality of its architecture, its maintenance, and above all, its production ethics. The future likely belongs to “FOSS-respecting” AI models. Unlike “opaque box” models, a “FOSS-respecting” approach does more than just comply with the law (such as the European AI Act). It goes further by guaranteeing true digital sovereignty. This specifically involves using models and datasets whose provenance is auditable. The idea here is to verify that no copyrights were violated during training. For an enterprise, choosing these tools becomes a major strategic asset. It represents a commitment to transparent technology. It establishes that compliance is community-verifiable, which eliminates any hidden legal liabilities linked to code “laundering.” This becomes a selling point. The company can market a clean, transparent technology, free from any concealed legal baggage.
Ethical Perspective
Beyond lines of code and contractual clauses, AI raises a fundamental ethical question that brings us back to a millennia-old inquiry. This is the philosophical thought experiment concerning the notion of identity, known as the Ship of Theseus. If every single plank of Theseus’s ship is replaced one by one until none of the original parts remain, is it still the same ship?
When applied to code, the dilemma is striking. We realize that AI can rewrite every line of syntax, optimize every function, and rename every variable, effectively replacing the linguistic “planks” of the original text. Yet, if the logical structure and functional architecture remain those of the initial work, can we truly claim to have created a new legal object?
This inquiry finds a direct echo in recent research, notably the study “A Ship of Theseus: Curious Cases of Paraphrasing in LLM-Generated Texts,” which highlights a disconnect between form and substance. When an AI paraphrases, we observe a prioritization of style over content. In other words, while the original author’s stylistic signature fades in favor of a generic imprint unique to the Gen AI model, the semantic content itself often remains intact. This phenomenon questions the “continuity of identity” of the work. According to this theory, as long as the fundamental attributes persist, whether it be the logical design or the function of the code, the object retains its original identity. We can see an analogy here with Da Vinci’s Mona Lisa. If a contemporary artist were to offer a version using fluorescent pigments or spray-paint techniques, the Renaissance “touch” would disappear in favor of a modern style. Yet, the work would still be recognized as Leonardo da Vinci’s. Why? Because the identity of the painting does not reside solely in the type of paint used, but in its geometric composition, the precise tilt of the gaze, the pyramidal structure of the subject, and so on. In this view, according to the study, authorship should remain with the initial creator as long as their unique concepts are preserved. Therefore, AI rewriting is merely a syntactic mask. It follows that one cannot justify a change in licensing or ownership based on such a transformation.
On the other hand, if one considers that the active act of transformation is what defines an author, then AI could be seen as the true creator of this new version. This ambiguity underscores that traceability has become a sine qua non for determining whether we are facing a mere writing aid or a true substitution of identity. For defenders of Open Source ethics, the answer is clear. They claims that changing the planks (the syntax) does not change the ship’s blueprints (the intellectual property), just as a Mona Lisa painted in pink remains the work of Da Vinci. In this light, AI facilitates appropriation without contribution, allowing one to claim ownership of a “new” vessel when they have merely masked the work of another. Thus, AI automates reformulation, offering the possibility to plunder a project’s intelligence without ever nourishing the ecosystem. This effortless “translation” dehumanizes source code, its authorship, and intellectual property. It transforms code into a raw commodity that can be appropriated through a simple prompt, ultimately shattering the principle of reciprocity that lies at the very heart of Open Source.
This techno-legal drift is giving rise to a crisis of attribution. The figures from the study “Permissive-Washing in the Open AI Supply Chain: A Large-Scale Audit of License Integrity” speak for themselves. According to the researchers, today, barely 5.75% of applications preserve the copyright notices of the models or datasets used. By erasing these mentions, we are not merely violating a legal rule, we are breaking the chain of recognition upon which the careers and reputations of developers depend. Now, code is being generated on such a massive scale that the original author tends to be drowned in the depths of machines and models. This systemic erasure risks discouraging the contributors of tomorrow, who may legitimately ask themselves: why offer their work to the community if an AI is to eventually digest it and spit it back out under an anonymous or, worse, proprietary banner?
Open Source DNA at the Core of Models
It is worth recalling a fundamental truth, often brushed aside in the marketing discourse of AI labs. By its very nature, Open Source Software forms the very backbone of every LLM. Since these models have been trained by blindly “scraping”, without authorization and even less remuneration, everything accessible online, open code is not merely a source of inspiration, it is, in fact, embedded in the very structure of the system. This means that, in essence, Open Source is an integral part of the model, regardless of the denials or semantic gymnastics of AI developers. As long as a developer cannot provide irrefutable proof of a completely “clean” training dataset (a certification that, in practice, will never happen!)the model remains fundamentally tied to the community work it has absorbed.
Conclusion
“AI Washing”, whether through license laundering or permissive washing, is not merely a technical issue or a debate for legal experts. It is a profound breach of the digital social contract that has bound creators and users together since the dawn of Open Source. By enabling the automation of appropriation without contribution, Generative AI risks transforming one of the finest examples of human collaboration into an anonymous data reservoir for proprietary software. Faced with this phenomenon, the question arises: are we forced to resign ourselves to a state of affairs where the notion of authorship must bow to the power of Gen AI? Or rather, will we be able to impose tangible traceability through “AI-Proof” mechanisms? The answer to this question will determine whether AI becomes a vehicle for sharing and innovation, or whether it acts as the catalyst for the end of Open Source by hijacking human contribution. For companies and developers alike, choosing transparent and respectful (FOSS-respecting) tools is no longer an ethical option. It is becoming a strategic necessity to preserve trust and the long-term viability of our software heritage.
The Ship of Theseus experiment leaves us with our backs against the wall. We must ask ourselves: if an entire ship is rebuilt using the planks removed from the original, which one is the true ship? By using AI to “launder” syntax, we create nothing, we simply displace ownership. If we accept that the machine can erase the origin of the wood to preserve only its shape, the very concept of sharing is called into question.
A sustainable ecosystem cannot be built on “laundered” code. By separating logic from its license, AI does not liberate software, it dispossesses it of its identity and its rights. The true danger is not that the machine will replace the developer, but that it will serve as a screen for unapologetic appropriation within a “shadow legal system.” Protecting attribution is not about slowing down progress, quite the opposite, it is about ensuring that the reservoir of common knowledge is not drained by the very people who refuse to replenish it.
How Generative AI is Compounding a Structural Crisis and Why Governments Must Act
Executive Summary
Open source software is the foundational infrastructure of the global digital economy. Estimates of its total economic value exceed $8.8 trillion. It underpins financial systems, healthcare networks, national security infrastructure, and the majority of commercial software products worldwide. It is maintained, overwhelmingly, by unpaid volunteers.
This paper argues that this arrangement was already structurally unsustainable before the emergence of generative AI tools, and that those tools have now materially accelerated this pre-existing decline. There is longitudinal evidence of a rising trend in open source project abandonment and contributor decline that pre-dates both the COVID-19 disruption and the AI adoption wave. This baseline goes a long way to establishing that the ecosystem was deteriorating under the weight of years of corporate free-riding on unpaid maintainer labor. Against this baseline, we assess three mechanisms through which generative AI is compounding the crisis:
the degradation of contribution quality and the associated acceleration of maintainer burnout
a novel and rapidly expanding security attack surface
the structural invisibility of both harms in the ROI framework organizations use, and through which AI adoption is currently evaluated and justified.
The logical upshot of this data is that we make a regulatory argument. The costs of AI misuse in the open source ecosystem are external, that is they are invisible to the measurement frameworks of the organizations generating them. Thus they are forced to be absorbed by a commons with no mechanism to charge the parties responsible. The open source commons has been given a decade to demonstrate otherwise, but it has shown that voluntary correction cannot be relied upon. The voluntary participation rate among open source users in the largest funding program is a staggeringly low 0.001 per cent. Put bluntly, the voluntary model has overwhelmingly and unambiguously failed.
The irony at the center of this crisis is not incidental, it is structural. The artificial intelligence industry, which has grown faster and extracted more commercial value from open source software than any preceding wave of technology adoption, is built almost entirely on open source foundations. The training infrastructure that powers large language models runs on open source frameworks. The model architectures are derived from openly published research with open source reference implementations. The data pipelines, evaluation harnesses, fine-tuning libraries, and deployment tooling are, with negligible exception, open source projects maintained by the same volunteer and underfunded contributor communities this paper documents as being in decline. AI companies did not merely benefit incidentally from the open source commons. They consumed it at scale, systematically, as a precondition of their existence. They are now, through the AI coding tools they sell into the developer market, one of the primary vectors for the contribution noise, quality degradation, and maintainer burnout that this paper documents as accelerating the commons’ deterioration. The industry that most depends on the commons is among those most actively degrading it. That is not a peripheral observation. It is the central justification for the policy response this paper proposes.
That proposal is the creation of a Sovereign OSS Fund. It would be a mandatory contribution mechanism, scaled proportionately to commercial benefit and AI deployment intensity. This mechanism would be similar to the existing models of the IMF/EU Central Bank and Federal Reserve Bank for fininancial regulation and maintenance. The Sovereign OSS Fund would be governed by an independent body operating outside both government and industry control, designed to function as a collective insurance pool against the systemic risk of critical digital infrastructure failure. The fund is not a tax. It is the price of operating responsibly in a shared digital economy whose foundations are disintegrating.
Introduction: The Open Source Bargain and Its Breaking Point
There is an implicit bargain at the foundation of the modern digital economy. Millions of software developers, working largely without payment, maintain the libraries, frameworks, and tools upon which the world’s largest technology companies have built products worth trillions of dollars. Those companies take the outputs freely, use them in their commercial products, and in theory, contribute back to the projects they benefit from. In practice, this translates either to contributing minimally or not at all to the maintenance of the infrastructure they depend upon. This arrangement has persisted for two decades, founded on the assumption that the goodwill of volunteer maintainers is an inexhaustible resource. It is not.
The signs of structural strain have been visible for years. Burnout rates among open source maintainers have been consistently above 50 per cent in every survey conducted since 2015. Critical infrastructure projects have been maintained by single individuals, or small groups, with no succession planning, no institutional support, and no compensation commensurate with the systems depending on their work. The Log4Shell vulnerability in 2021 exposed this dependency to the world. It was a critical flaw in a library maintained by two volunteers, that threatened hundreds of millions of systems globally. Estimates put the cost to the private sector at an estimated $100 million or more in remediation. It received the attention of governments and security agencies worldwide, and many expected corporations to take from that episode. It revealed in stark terms that they had a duty of care to the infrastructure they depended upon. Unfortunately, as is so often the case when the cost is invisible to the bottom line, this lesson was lost on the organizations in question. The voluntary participation rate in open source funding programs did not materially improve.
Into this deteriorating landscape emerges generative AI, and the advent of the “citizen developer”. Beginning in late 2022, AI coding assistants became widely available to enterprise software developers and hobbyists alike, and their adoption has been rapid. These tools are capable of generating code, identifying bugs, and drafting documentation at unprecedented scale and speed. Critically, as the tools have improved, they have also become capable of autonomously submitting contributions to open source projects in the form of pull requests and issue reports. Their deployment at scale by large commercial organizations, and ease-of-use by amateur coders has introduced a new category of stress into a system already under strain. Maintainers now face a flood of AI-generated contributions requiring human review, often containing higher error rates, and more subtle and hard to identify errors, than human-authored code. The errors are part of the tools themselves, hallucinations, and security vulnerabilities that these AI models often produce. Unfortunately they are also arriving faster than the volunteer maintainer community can process them. Several prominent projects have already changed their governance structures or closed to external contributions in response. Others have been retired, or effectively closed their programs entirely.
At it’s core, and based on all these factors, this paper makes three basic supporting arguments for its ultimate policy recommendation:
The decline of the open source ecosystem is not a new phenomenon caused by AI, but a pre-existing structural failure that AI is now meaningfully accelerating. The distinction matters for policy: the appropriate response to an AI-caused problem is AI regulation; the appropriate response to a structural market failure that AI is worsening is structural market reform.
The harm AI is causing to the open source commons is currently invisible to the corporate decision-making frameworks through which AI adoption is evaluated, and that this invisibility is the foundational reason why voluntary self-regulation cannot be expected to produce adequate results.
That governments have allowed this situation to develop through a combination of deference to industry self-regulation and a failure of their own measurement frameworks, and that the time for that deference has passed.
The policy proposal at the center of this paper, the creation of the Sovereign OSS Fund, is designed as a structural response to a structural problem. It does not restrict AI adoption, nor does it seek to regulate it. Instead, it requires that organizations adopting AI at scale bear, proportionately, the costs of maintaining the underlying infrastructure their adoption is degrading. It is governed independently of both government and industry to prevent the capture that has historically undermined similar initiatives. And it is framed, deliberately, not as a punitive instrument but as a collective insurance pool against a systemic risk that every participant in the digital economy shares.
Argument 1: The Pre-Existing Fragility — A Decade of Structural Deterioration
Any accurate account of what generative AI is doing to open source must begin before AI. The argument that AI is the cause of the ecosystem’s current difficulties is both analytically incorrect and politically misleading. It locates the problem in a disruptive technology, rather than in the structural conditions that made the technology’s impact so damaging. The ecosystem was already failing, with meaningful declines in participation and volume of activity on projects already in evidence since well before the advent of AI tools. Understanding why the system is in such a state, requires examining the last two decades of a system of dependency without reciprocity.
1.1 The Scale of the Dependency and the Vacancy of the Contribution
The economic value of open source software is difficult to overstate. A 2024 study from Harvard Business School estimated the total value of freely available open source code at $8.8 trillion. It concluded that if companies were required to replicate that software using proprietary development, the cost would be 3.5 times higher than current expenditure on commercial software globally. Just south of $30 trillion, or the entire GDP of the United States to find an applicable comparison. To say the impact of the loss of this infrastructure would be seismic is perhaps the understatement of all time.
The maintenance of this infrastructure is provided overwhelmingly by unpaid volunteers. The 2024 Tidelift State of the Open Source Maintainer Report found that 60% of maintainers describe themselves as unpaid hobbyists. The Linux Foundation’s Census II study found that 136 individual developers were responsible for more than 80 per cent of the code committed to the top 50 open source packages. These are not secondary utilities. They include the cryptographic libraries, authentication frameworks, network protocols, and data processing tools upon which the majority of commercial software infrastructure is built.
The contribution gap, the distance between the value extracted and the maintenance investment returned, is the structural condition from which everything else in this paper follows. It is not new, and it is not narrowing. GitHub Sponsors, the largest voluntary funding mechanism for open source maintainers, has grown to approximately 4,200 corporate participants out of an estimated 300 million companies worldwide that use open source in commercial products. This is a voluntary participation rate of approximately 0.001 per cent. The voluntary model has had a decade to demonstrate that the private sector will voluntarily maintain the commons it depends upon. It has not done so.
1.2 The Human Cost: Burnout and the Exit of Experienced Maintainers
The sustainability crisis is not primarily a financial one, though finance is a component. It is a human one. Maintainers are leaving open source projects, not because they have been offered better employment elsewhere, but because the work has become untenable. The 2024 Tidelift survey found that 60 per cent of maintainers had quit or seriously considered quitting due to burnout, a figure statistically unchanged from the prior year’s 58 per cent despite sustained public awareness of the problem following Log4Shell.
The causes of burnout are consistent across surveys and qualitative accounts: the volume of inbound issue reports and pull requests; the expectation of responsiveness from commercial users of projects maintained in personal time. The exposure to harassment and entitlement from users who treat open source maintainers as unpaid support staff for commercial products. And not least of all, the psychological weight of knowing that critical infrastructure used by millions of people depends on one’s continued personal availability. These are not problems that can be solved by occasional financial contributions. They require structural changes to how the open source commons is governed and resourced.
The loss of experienced maintainers has a compounding effect that is structurally more damaging than the headline burnout figures suggest. When a maintainer with years of context about a project’s architecture, security considerations, and dependency graph leaves, that knowledge is generally not recorded. The project does not produce a transition document. The next maintainer, if there is one, begins with a fraction of the institutional knowledge that left, and a learning curve to understand the software as it is today. This is the mechanism by which the single-maintainer dependency problem becomes a security vulnerability: not when the maintainer burns out, but when the replacement, or the absence of any replacement, creates a gap that determined adversaries can exploit. The XZ-Utils incident, in which a sophisticated multi-year social engineering campaign nearly installed a backdoor in the majority of the world’s Linux distributions through a single maintainer’s exhaustion and consequent susceptibility to a seemingly helpful new contributor, is the clearest illustration of where this leads.
1.3 The Concentration Problem: Single Points of Failure at Scale
The Linux Foundation’s Census II methodology identified a specific and underappreciated dimension of the fragility: it is not simply that open source is under-resourced overall, but that the under-resourcing is extreme at precisely the most critical points. The finding that 136 developers are responsible for more than 80 per cent of contributions to the top 50 packages means that the global digital economy has, in practical terms, approximately 136 single points of failure in its most critical software infrastructure. This is before any consideration of the long tail of smaller but still critical projects below that top tier.
The concentration problem is made worse by the invisibility of dependency relationships to the organizations that have them. A financial services firm with a multi-billion-dollar technology budget may have no awareness that one of its core authentication systems depends on a library maintained by a single individual in their personal time, using personal equipment, with no institutional support and no succession plan. The SBOM (Software Bill of Materials) mandates introduced by the Biden administration’s 2021 Executive Order on Cybersecurity were designed, in part, to address this visibility gap. They are a necessary but far from sufficient response to the underlying risk.
1.4 What Corporate Engagement Has Looked Like in Practice
It would be inaccurate to suggest that corporations have done nothing. Several large technology companies have established open source program offices, contributed employees to the maintenance of critical projects, and made financial commitments to open source foundations. These efforts are real, and do make a meaningful difference. They are also structurally insufficient to stem the bleeding of the ecosystem as a whole. The data clearly shows that they concentrated among a small number of technology companies, weighted toward projects of direct commercial relevance to those specific companies’ products, and disconnected from the long tail of critical infrastructure that receives no equivalent support.
The pattern that emerges from the evidence is one of extractive dependency. Corporations that have built significant portions of their product value on open source foundations, and that have not reciprocated at a level commensurate with that extraction. The Harvard HBS figure of $8.8 trillion in value, time 3.5x replacement costs, is a measure of what those corporations would need to spend to replicate what they currently receive for free. Against that figure, the aggregate corporate investment in open source maintenance is vanishingly small. This is not primarily a result of bad faith, no one wants to actively kill off open source. It is a result of a measurement framework that accounts for the value received but not the cost of providing it, and an incentive structure that rewards free-riding as long as the commons holds.
Argument 2: The Longitudinal Abandonment Trend — A Pre-Existing and Worsening Crisis
Establishing that open source project abandonment was rising before the AI adoption wave is the central evidentiary task of this paper. It is also the task on which the paper’s regulatory argument most directly depends. If AI caused the crisis, the appropriate policy response is AI regulation. If the crisis pre-dates AI and AI is accelerating it, the appropriate policy response is structural, and must address the market failure that made the ecosystem vulnerable, with AI governance as a component rather than the totality of the solution. This section presents existing secondary evidence, based on our own original primary research using GHArchive public data, and a framework for interpreting what the combined evidence shows.
2.1 Existing Evidence of Pre-AI Decline
Several peer-reviewed studies establish that open source project abandonment was rising before generative AI tools became widely available. Coelho et al. (2019) found a 16 per cent abandonment rate in a sample of 1,932 popular GitHub projects, identifying maintainer overwork and declining community engagement as the primary drivers. This study, published before any significant AI coding tool adoption, documents a baseline condition of structural fragility that existed independently of the AI question.
The more substantial dataset comes from Xu et al. (arXiv 2507.21678, 2025), which analyzed 115,466 GitHub repositories and confirmed abandonment in 57,733 of them, using a multi-factor methodology that filtered for genuine project inactivity rather than simply the absence of recent commits. This dataset is, to date, the largest systematic abandonment analysis in the literature. Its primary limitation for the purposes of this paper is that it was published as a predictive modelling framework rather than a time-series analysis: it identifies abandoned projects but does not provide year-by-year disaggregated data that would allow a trend line to be constructed.
The Tidelift maintainer survey series provides complementary evidence from the supply side. Rates of burnout, quitting, and seriously considered departure among open source maintainers have been consistently above 55 per cent in every Tidelift maintainer survey conducted between 2021 and 2024, a figure the surveys themselves describe as essentially unchanged year on year despite growing public awareness of the problem. The consistency of these figures across four consecutive annual surveys is itself the most damaging evidence against the voluntary action argument. Awareness of the crisis has not moved the needle. The surveys do not provide the project-level longitudinal data that would allow a contributor attrition trend line to be constructed, but they establish the human context within which the quantitative findings in Section 2.3 should be read.
2.2 Primary Research: The GHArchive Analysis
To establish a longitudinal trend line from primary data, this paper presents original analysis of the GHArchive public dataset, covering the period 2015 to 2025. GHArchive is a public archive of GitHub’s event stream, capturing push events, pull request events, issue events, and contributor activity across the full population of public GitHub repositories. The analysis focuses on a filtered set of high-longevity repositories selected to represent consequential open source infrastructure rather than the long tail of personal and experimental projects.
Methodology and filtering criteria
The filtering methodology adapts the multi-factor approach of Xu et al. to the fields available in the GHArchive event stream. Repositories were required to meet all of the following criteria to be included in the analysis: a minimum of seven years of continuous activity within the study window; a minimum of five distinct contributors at peak year engagement; a minimum of 100 activity events per year in active years (approximately two meaningful actions per week on an annualized basis) to distinguish sustained maintenance from occasional personal activity; and exclusion of known noise patterns including repository names consistent with tutorial, course, homework, dotfiles, demo, example, and curated list repositories. Repositories with a pull-request-to-push ratio below 0.01 were excluded as probable automated mirrors.
The analysis tracks four primary metrics across each year in the study window:
total activity events
distinct contributor count by GitHub login
push events as a proxy for direct commit activity
pull request events as a proxy for external contribution volume.
The distinction between push and pull request event trends becomes analytically significant in the 2023 data, as discussed in Section 2.3.
The dataset covers 2015 to 2025. Data prior to 2015 exists in the GHArchive record but is treated with caution given documented inconsistencies in GitHub’s early event capture; 2015 is the more defensible starting point for the quantitative trend line.
Known limitations
The GHArchive event stream captures activity but cannot distinguish the origin of that activity. A pull request submitted by a human developer and one generated by an AI coding tool appear identically in the event record. This limitation is directly relevant to the interpretation of the 2023 data discussed in Section 2.3, and the paper is explicit about what can and cannot be established from aggregate event counts alone. The contributor count metric uses distinct GitHub logins per year, which will under count contributors operating under multiple accounts and over count bots or automation scripts operating under named accounts. These limitations are acknowledged and do not materially affect the directional findings.
Note on forthcoming research: A natural extension of this analysis is tracking individual contributor logins across repositories to distinguish migration from complete exit. While it is technically feasible using the same GHArchive dataset, it is outside the scope of this paper. A targeted version, tracking the 2019 Gatsby contributor cohort against successor frameworks Next.js and Astro in 2021–2023, is planned as a companion study. The question of whether contributors who leave established projects migrate to newer ones or exit open source contribution entirely has significant implications for the policy argument. A migration suggests the contributor pool is redistributing, while a full exit confirms the net depletion the Tidelift surveys describe from the supply side. This forthcoming research is flagged here as a known gap that the current analysis cannot resolve from aggregate event data alone.
2.3 Findings: The Longitudinal Trend
Analysis of the filtered repository set across the full 2015–2025 study window reveals a pattern that has moved, in the period since the original draft of this section, from predictive to descriptive. The stress accumulation model advanced in Section 1 is no longer a projection of where the open source ecosystem is heading. The data documents where it has already arrived.
Before presenting the findings it is worth establishing the analytical frame. The dataset does not show uniform collapse, and the paper does not claim that it does. It shows a clear and consistent bifurcation between two categories of project. The first category, those projects whose institutional backers have direct, ongoing, profit-motivated investment in sustaining their contributor ecosystems, shows stability or modest decline. The second category, those projects that are commercially critical but whose backers extract value from them without commensurate contributor investment, shows sustained and in many cases accelerating decline. Notably, the 2024 and 2025 data reveals a cliff that the 2015–2023 trend line had been building toward for almost a decade. The bifurcation is the finding. It is not a caveat to the argument. It is the argument.
The pre-COVID baseline deterioration (2015–2019)
Among projects with nine or more years of continuous activity in the dataset, the majority show declining or flat contributor counts between 2015 and 2019. Apache Spark declined from 1,165 distinct contributors and approximately 177,000 total events in 2015 to 741 contributors and 127,000 events by 2019. This was a 36 per cent reduction in the active contributor base during a period of strong and growing enterprise adoption. Elastic Kibana peaked at 2,639 distinct contributors in 2016 and had declined to 2,208 by 2019 despite substantially increased event volume, the earliest instance in the dataset of the concentration dynamic. That is when a shrinking contributor pool is absorbing a growing workload. gRPC peaked at 1,761 contributors in 2017 and had begun a decline that would prove uninterrupted through 2025. Laravel/framework peaked at 4,059 contributors in 2017 and declined steadily thereafter. Golang/go reached its contributor peak of 4,996 in 2019 before beginning a decline that would continue without interruption to 2025.
The pre-COVID pattern is significant because it establishes that contributor attrition in established projects was underway before either the COVID disruption or the AI adoption wave. It was not caused by either, but they accelerated it.
The 2020 disruption
The 2020 data shows a marked increase in activity across the majority of projects in the dataset, consistent with the well-documented surge in open source contribution accompanying the shift to remote working during the COVID-19 pandemic. TensorFlow reached its peak contributor engagement of 10,796 in 2020. Flutter reached its all-time peak of 19,666. Rust reached 3,536. Homebrew peaked at 1,014. Apache Spark was the notable exception to this rule. Its contributor count continued falling through 2020 from 741 to 651, as a project whose structural decline was already too advanced for the broader ecosystem trend to reverse.
The 2020 data is treated throughout this analysis as an external disruption rather than a structural signal. Its analytical significance lies entirely in what the recovery looks like in the years that follow.
The incomplete recovery (2021–2022)
Across the majority of established projects in the dataset, the 2021–2022 period does not return to 2019 levels. It settles at a lower floor. Kubernetes declined from its peak of 6,606 contributors in 2019 to 4,060 by 2022. Elastic Kibana fell to 1,517, 42% below its 2016 peak. Flutter fell from 19,666 in 2020 to 11,926 by 2022, a 39% decline in two years. TensorFlow fell from 10,796 in 2020 to 3,872 by 2022, a 64% decline in two years, despite sustained internal Google development activity throughout. Gatsby, whose collapse began before the COVID disruption, fell from 5,947 contributors at peak to 1,505 by 2022 — an 87 per cent decline driven primarily by the Netlify acquisition and the community exit that followed it.
The system emerged from the 2020 disruption weaker than it entered it. The post-COVID floor was lower than the pre-COVID baseline across virtually every project in the declining category.
The 2023 AI noise signal
The 2023 data shows a pattern consistent with the AI contribution noise hypothesis advanced in Section 3. Several projects show partial stabilization or modest recovery in total event counts. Year-on-year, Kubernetes was flat at 145,152, Elastic Kibana was flat at 192,022, Rust marginally up, even while distinct contributor counts continued to fall. For Kubernetes, contributors fell from 4,060 to 3,420 despite flat event totals. TensorFlow’s push events remained stable while PR events collapsed from 5,239 to 2,421, consistent with continued corporate-driven development and a near-complete withdrawal of external community contribution.
This event-contributor divergence, appearing consistently across multiple projects in the first full year of mass AI coding tool adoption, is consistent with AI-generated activity inflating event counts while the human contributor base continues its structural contraction. It must be very clearly stated that this cannot be established definitively from aggregate event data alone. Distinguishing AI-generated from human-generated contributions in the GHArchive event stream requires contributor-level analysis beyond the scope of this study, but the directional pattern is consistent with what AI-generated contribution noise at scale would produce, and is consistent with the qualitative evidence from named projects in Section 2.4.
The 2024–2025 acceleration: the reckoning arrives
The 2024 and 2025 data represent the most significant finding in this analysis. What the 2015–2023 trend line had been building toward as a projection has arrived as a measured reality. Across the majority of established projects in the dataset, 2024 and 2025 show accelerating contributor collapse that in several cases returns projects to or below their pre-growth baselines. In just two years a decade of community contribution is erased, while the commercial infrastructure built on those projects has never been larger or more deeply embedded. These are some important and illustrative examples, but the list of declines is many, many times longer than presented here.
Kubernetes fell from 3,420 contributors in 2023 to 3,098 in 2024 and 2,365 in 2025. Meanwhile, its total events in 2025 were 93,627, almost exactly its 2015 level of 94,419. A project that grew from a standing start to become the de facto standard for enterprise container orchestration globally has returned, on contributor engagement, to where it began. The commercial dependency on Kubernetes has never been greater. The community sustaining it has never been smaller relative to that dependency.
Flutter fell from 11,399 contributors in 2023 to 10,364 in 2024 and 7,115 in 2025. Its total events of 91,653 in 2025 were the lowest since 2018, when Flutter was a niche project with minimal adoption. Despite the demonstrable fact that it now underpins hundreds of millions of deployed applications across iOS and Android.
Apache Spark, admittedly a project that would be considered “legacy” in some circles, but is still widely deployed in analytics workflows globally, reached 523 contributors and 18,167 total events in 2025, below its 2015 starting point of 1,165 contributors and 177,222 events on both metrics.
Golang/go fell to 2,711 contributors in 2025, a 46 per cent decline from its 4,996 peak.
gRPC fell to 632 contributors, a 64 per cent decline from peak, with push events rising in 2024–2025 in a pattern consistent with internal automation replacing community contribution.
Laravel/framework fell to 1,675 contributors in 2025, its lowest recorded level.
TensorFlow presents the most analytically complex 2024–2025 pattern in the dataset and warrants specific treatment. Total events spiked to 111,654 in 2024, the highest since 2020, while distinct contributors collapsed to 2,921. In 2025, events remained elevated at 93,418 while contributors fell further to 1,222. Push events exploded from approximately 15,000 per year across 2021–2023 to 56,756 in 2024 and 47,013 in 2025. PR events similarly spiked from around 2,400–7,300 in prior years to 31,361 in 2024 and 34,214 in 2025. The result is that 1,222 distinct contributors generated 93,418 events in 2025. That’s an average of approximately 76 events per contributor, compared to approximately 9 events per contributor at peak community health in 2019 the last “regular” year of data. This is the most extreme event-contributor divergence in the dataset. It is consistent with a project that has become primarily a vehicle for internal Google automation and AI-generated contribution activity, with its open source community having almost entirely disengaged. That Google’s primary AI framework, has reached this state is not a footnote – vast swathes of the AI ecosystem would not exist without Tensorflow and it’s overall capabilities. It is a summary of the paper’s argument in a single data series.
WordPress/Gutenberg warrants specific attention given its infrastructural significance, and its 2024–2025 trajectory is more explicable, and more instructive, than the raw numbers alone suggest. Events of 101,447 and contributors of 2,019 in 2024 were followed by 34,422 events and 1,191 contributors in 2025. That is a 66 per cent single-year event collapse and a 41 per cent contributor decline in one year. WordPress powers approximately 40 per cent of the public web. Gutenberg is its core editing interface. The proximate context for this decline is the highly public dispute between Automattic and WP Engine in late 2024, which produced governance instability, community polarization, and a measurable withdrawal of developer engagement at precisely the moment Automattic was accelerating its AI integration strategy. The data suggests a compound mechanism: governance-driven community exit amplified by developer push-back against an AI-first strategic direction imposed by the corporate backer without community consensus. If that interpretation is correct, something subsequent qualitative research is required to confirm, then Gutenberg represents a new category of decline mechanism not previously identified in this dataset. Active contributor withdrawal in response to corporate AI encroachment on a project’s identity and direction, rather than the passive attrition through burnout and neglect that characterizes the majority of declining projects. The policy implication is that AI strategy decisions made unilaterally by corporate backers can destroy contributor communities rapidly and at scale, adding a further dimension to the governance argument developed in Section 5.
The counter-examples and what they prove
A handful of projects in the dataset show stability or growth in 2024–2025, and their characteristics are analytically decisive.
Visual Studio Code — Microsoft’s code editor and the primary host for every major AI coding extension on the market shows events of 144,669 in 2024 and 150,398 in 2025, with contributors of 20,579 and 19,982 respectively. Essentially it is flat across three years ending 2025. Microsoft has direct, measurable, ongoing commercial incentive to maintain VS Code’s contributor ecosystem. It is significant that it is the delivery mechanism for GitHub Copilot, which is a significant and growing revenue line. It’s project stability is not coincidental. It is the product of active investment.
Hugging Face Transformers — the most widely deployed model fine-tuning and serving library in the AI industry shows events of 52,959 in 2024 declining to 40,072 in 2025, with contributors of 4,904 and 3,515 respectively. A meaningful 2025 decline, but from a high base, and 2025 levels remain above 2021 and 2022 unlike other projects. The AI industry has direct commercial incentive to maintain this library’s contributor ecosystem. The relative resilience, compared to projects where that direct incentive is absent, is consistent with the pattern.
NixOS/nixpkgs reached its all-time peak of 407,677 events and 9,644 contributors in 2024 before a modest pullback to 350,974 events and 8,896 contributors in 2025. It remains the one project in the dataset showing sustained community-driven growth without clear corporate profit motivation as the primary driver. This is a genuine exception, explicable by the combination of strong foundation governance, an ideologically committed community, and technical characteristics that attract sustained new contributor interest. It is the dataset’s proof that the structural conditions for sustainability are achievable. It is also, notably, the only project in the dataset for which that can be said in the absence of direct corporate profit motivation.
Homebrew/homebrew-core shows a more ambiguous picture that is worth flagging as a warning signal rather than a counter-example. Total events grew through 2024 (201,202, the highest in its history) before a modest 2025 pullback to 191,936. But distinct contributors have been falling steadily and without interruption: from 3,114 in 2017 to 1,410 in 2025, a 55 per cent decline across eight years. Homebrew-core is doing substantially more work with substantially fewer people. The event volume is being maintained while the contributor base sustaining it is quietly contracting. This is the concentration dynamic in its most developed form. It is not yet a cliff, but with the preconditions for one accumulating year on year.
Rust-lang/rust shows a 2025 anomaly that requires a methodological note. Contributors fell from 4,257 at peak to 2,926 in 2025, continuing the gradual decline visible since 2022. However, push events spiked sharply in 2025 to 12,130. That’s nearly five times the 2024 level of 2,722 and the highest push event count in the project’s recorded history. Interesting because it happens with no corresponding announcement of a large-scale internal engineering initiative in the Rust project’s published 2025 roadmap and blog record. The most simple explanation, consistent with the broader patterns observed in this dataset, is that Rust is experiencing significant AI-generated or automated push activity. Rust’s technical prestige and community prominence make it a plausible target for low-effort, AI-assisted contributions, by actors seeking visibility in a high-status project. This hypothesis will be explored in subsequent research using contributor-level analysis. For the purposes of this paper, the Rust contributor count trend, declining but not collapsing and remaining substantially above pre-COVID levels, is treated as the more reliable signal of community health, and the 2025 push event spike is flagged as an unverified anomaly rather than an organic community signal.
The pattern and what it means
The bifurcation across this dataset is not random and it is not explained by project age, language, domain, or corporate affiliation in the simple sense. What distinguishes the stable projects from the declining ones is a single variable: whether the institutional backer has direct, ongoing, profit-motivated incentive to invest in the contributor ecosystem specifically. The backer(s) aims to fully use the project, not merely to employ engineers who commit to it, but to actively sustain the community that maintains it.
Microsoft invests in VS Code’s contributor ecosystem because VS Code is the distribution mechanism for Copilot revenue. Hugging Face invests in Transformers because Transformers is the product. NixOS’s community invests in itself because the community is the product. In every other case in the dataset, the institutional relationship is extraction. The project is used, depended upon, and in some cases nominally sponsored, but the contributor ecosystem is not actively maintained as an asset. It is consumed as a commons.
The result is visible in the data across a decade. Commercial dependency without active contributor investment is not protection. It is a slow-motion depletion of a shared resource. The projects in this dataset that are declining are not failing because they are bad projects or because their maintainers are insufficiently dedicated. They are failing because the market structure that surrounds them systematically rewards extraction and systematically fails to fund maintenance. That market failure is what this paper’s policy proposals are designed to address.
2.4 Case Studies: Projects at the Breaking Point
The quantitative trend data is supplemented with named case studies that illustrate the mechanisms at work. Four cases are particularly instructive, each representing a different point on the failure spectrum from governance change to active security exploitation.
Ingress NGINX was retired from active development in November 2025. It is not a peripheral project: it was the default ingress controller for Kubernetes clusters globally, underpinning enterprise infrastructure across financial services, technology, and public sector deployments. Its retirement was not caused by a lack of corporate sponsorship — it had that. It was caused by a lack of human attention: the maintainers, facing an increasing volume of AI-generated pull requests requiring review, and carrying the cognitive overhead of a project whose architectural complexity had grown beyond what a small volunteer team could sustainably manage, simply reached the end of their capacity.
curl, one of the most widely deployed command-line tools in the world, paused its bug bounty programme in 2024 after receiving a flood of AI-generated bug reports that described non-existent vulnerabilities, consuming maintainer time without producing security improvements. The decision was documented publicly by the lead maintainer, providing a rare first-hand account of the mechanism by which AI degrades maintainer sustainability.
tldraw, an open source drawing tool with widespread use in commercial products, temporarily blocked all external pull requests in response to what its maintainers described as a volume of AI-generated contributions that overwhelmed their capacity for review. The block was a pragmatic response to a denial-of-service attack on maintainer attention, using the language of one of the project’s own contributors.
XZ-Utils, a data compression library present in the majority of Linux distributions, was the target of a multi-year social engineering campaign that came within a routine system update of installing a backdoor in global SSH infrastructure. The attacker exploited a maintainer in visible distress, who was overwhelmed, and publicly expressing difficulty keeping up. They did this by offering sustained, high-quality contributions over months before embedding a malicious payload. This case pre-dates AI-assisted attacks but illustrates the attack surface that AI dramatically widens. A maintainer under stress, with insufficient capacity to review contributions thoroughly, is the vector. A huge volume of low-effort AI submissions is the smokescreen. ~A single malicious contribution is the payoff.
Argument 3: How Generative AI is Worsening the Crisis in Three Mechanisms
This section is not an argument that generative AI is intrinsically harmful to open source. Some maintainers are using AI tools to manage their own triage, documentation, and code review workloads. Some projects have benefited from AI-assisted contributions that improve code quality. The argument is narrower and more specific. It is simply that generative AI, as deployed at scale by commercial organizations without governance frameworks adequate to the task, is net-negative for the structural health of the open source ecosystem through three distinct mechanisms.
3.1 Contribution Quality Degradation and the Asymmetric Burden
AI coding assistants are capable of generating a lot of very plausible-looking code, very quickly. They are significantly less capable of generating high-quality and accurate code, particularly in the context of large, complex, long-lived projects with intricate dependency relationships and non-obvious invariants. The gap between plausible and accurate is not random, rather it is systematically biased toward certain failure modes that are expensive for maintainers to detect and reject.
The Carnegie Mellon University study analyzed 807 open source GitHub repositories that adopted Cursor between January 2024 and March 2025, tracking code quality metrics through to August 2025. It found no reversal in quality degradation trends even as the underlying models improved substantially across the same period. The GitClear analysis of 153 million lines of committed code found that code duplication increased from 8.3 per cent to 12.3 per cent between 2021 and 2024, and that refactoring activity, the deliberate improvement of code structure by developers who understand it deeply, collapsed from 25 per cent of commits to fewer than 10 per cent over the same period. Code that is duplicated is code that is not understood, Code that is not refactored is code that accumulates technical debt. Both are indicators of AI-generated contributions being accepted into codebases without the quality of human review that the original contribution volume warranted.
The CodeRabbit analysis found that AI-generated code creates approximately 1.7 times as many code review issues as human-authored code. The asymmetry is the critical point. The entities generating the increased volume of contributions incur none of the cost of reviewing them. The commercial organization whose developer submitted a pull request using an AI tool bears no cost if that pull request requires multiple rounds of review from a volunteer maintainer. The maintainer bears the entire cost. This asymmetry is the externality structure that markets cannot self-correct.
The phenomenon has been characterized by practitioners as ‘vibe coding’, the generation of contributions that appear to address a stated issue but that have not been verified by the submitter against the actual system, and that may contain subtle errors, incorrect assumptions, or changes to unrelated parts of the codebase. By early 2026, curl, tldraw, and Ghostty had all changed their contribution policies directly in response to this phenomenon. The Ingress NGINX retirement, noted above, represents the highest profile example of the end state of the trajectory these policy changes are attempting to forestall.
3.2 Security Escalation: From Quality Degradation to Attack Vector
The security implications of AI-assisted development extend beyond the quality issues discussed above. AI tools introduce a distinct category of security risk that operates at the architectural level rather than simply the code quality level, and that is substantially more difficult to defend against.
Apiiro’s analysis of Fortune 50 enterprises found a ten-fold increase in security findings per month between December 2024 and June 2025. Research from multiple independent sources consistently finds that between 15 and 25 per cent of AI-generated code contains security vulnerabilities. A 2024 academic study found that between 5 and 22 per cent of the package names referenced in AI-generated code do not exist. This is a phenomenon that has given rise to a novel attack category. When AI models hallucinate package names and developers submit code referencing those names to open source repositories, attackers can register the hallucinated names with malicious payloads. Any project or user that subsequently installs the dependency as referenced in the accepted code receives the attacker’s payload. This attack vector, termed ‘slopsquatting’ by researchers, requires no compromise of any existing package; it exploits the hallucination behavior of AI coding tools directly.
Georgetown University’s Center for Security and Emerging Technology has documented a more sophisticated variant already in use. The AI models themselves can be targeted with data poisoning attacks that cause them to recommend malicious packages to developers using AI coding tools. This attack operates at the model level rather than the code level, and is therefore invisible to conventional code review processes. A developer using an AI assistant that has been poisoned to recommend a particular malicious dependency may receive that recommendation across all of their coding sessions, across all projects, before any individual project maintainer has the opportunity to reject a pull request.
The OpenSSF has explicitly noted that AI lowers the cost and sophistication barrier for supply chain attacks on open source infrastructure. The XZ-Utils attack, which required years of sustained, high-quality human engagement to execute, represents the high end of the sophistication spectrum prior to AI assistance. The tools now available to attackers make equivalent attacks substantially cheaper to mount, substantially easier to scale, and substantially harder to detect. Phylum’s analysis found more than 35,000 malicious packages in open source repositories, with an eight-fold increase in critical malware detection over the survey period.
Key Finding: AI is not merely introducing more vulnerable code into open source repositories. It is lowering the barrier to sophisticated supply chain attacks on critical infrastructure. The combination of maintainer burnout, reduced review capacity, and AI-enabled attack sophistication creates a risk environment that is qualitatively different from the pre-AI baseline.
3.3 The Measurement Problem: Invisible Externalities
The third mechanism is structural rather than technical, and it is in some respects the most important. The harm that AI is causing to the open source commons is systematically invisible to the corporate frameworks through which AI adoption is evaluated and justified. This invisibility is not incidental. It is a feature of how ROI is measured in large organizations, and it is the foundational reason why the problem cannot be solved by appeals to corporate self-interest or voluntary action.
The December 2024 IBM study on AI return on investment surveyed 2,413 IT Decision Makers at large enterprises. It found that 51 per cent reported positive ROI from AI adoption in software development contexts. The study is routinely cited by AI vendors and enterprise technology advocates as evidence that AI delivers measurable value to software development. A close examination of its methodology reveals why it cannot support that conclusion in the context of open source.
The respondents are director-level or above, with purchasing authority over IT products. They are, structurally, the people whose professional role is to justify the purchasing decisions they have made. The metrics used to calculate ROI, in this study: faster software development, faster innovation, time savings in productivity, are self-reported estimates at the individual level. They are also measuring the output of the developer using the tool, not the total system impact including downstream costs. The study measures the value the AI tool appears to produce in the transaction where it is used. It does not and cannot measure the costs imposed on maintainers reviewing the output of that tool, on security teams addressing the vulnerabilities it introduces, or on the shared infrastructure degraded by its aggregate use across the industry.
This is not a failure of IBM’s researchers. It is a description of the limits of ROI as a measurement framework for systemic externalities. The costs are real, they simply fall outside the boundary of the measurement. When an open source maintainer spends an additional hour reviewing an AI-generated pull request that turns out to be incorrect, that hour appears nowhere in any corporate ROI calculation. When a security team responds to a supply chain attack that exploited a hallucinated package name, the attribution to AI tool usage is invisible. The negative externalities are diffused across the commons and therefore unaccountable in any individual firm’s ledger.
The executive-developer perception gap is the human face of this measurement failure. The Atlassian 2025 State of DevEx Survey found that 63 per cent of developers report that their leaders do not understand their pain points, a sharp increase from 44 per cent the prior year, with developers specifically identifying the disconnect between leadership enthusiasm for AI productivity and developer experience of AI-generated review burden as a primary source of frustration. The EY Work Reimagined Survey of 15,000 workers found that 64 per cent perceive increased workloads despite widespread AI adoption, with only 5 per cent using AI in genuinely transformative ways. The METR randomised controlled trial is perhaps the most damning of all for the impact of AI on software development. It found that experienced developers took 19 per cent longer on tasks when using AI tools, despite believing, in a pre-trial estimate, that AI had made them 20 per cent faster. The perception gap runs in the wrong direction even at the practitioner level; at the executive level, it is wider still.
Part 4: The Externality Structure — Why Markets Cannot Self-Correct
The preceding three sections establish the empirical case: the open source ecosystem was already deteriorating before AI, AI is worsening it through identifiable mechanisms, and the harm is invisible to the measurement frameworks of the organizations causing it. This section makes the structural argument: that these conditions together constitute a classic negative externality that markets cannot self-correct, and that the historical record of voluntary action confirms this at scale.
4.1 The Externality Defined
A negative externality exists when the costs of a private action are borne by parties outside the transaction in which the action is taken, and where the acting party therefore has no market signal incentivizing cost reduction. Pollution is the canonical example: the factory producing pollution bears none of the cost of the health damage it causes to downstream communities, and therefore has no financial incentive to reduce pollution absent regulation. The incentive for self-regulation is structurally absent because the internal cost-benefit calculation of the polluting firm does not register the costs it is externalizing.
The open source situation has precisely this structure. The commercial organization that deploys an AI coding tool at scale incurs the cost of the tool license and the time its developers spend using it. It receives the benefit of apparently accelerated output. It does not incur the cost of the additional review burden imposed on open source maintainers, the security vulnerabilities introduced into shared infrastructure, or the accelerated burnout of the volunteer community whose continued unpaid labor it depends upon. All of those costs are externalized onto the commons. The commons has no mechanism to charge the externalizing party. The externalizing party has no incentive to reduce its externalization because its internal metrics do not register it.
The analogy to environmental regulation is instructive as a policy logic and not merely a rhetorical device. When private actors extract value from a shared resource while externalizing degradation costs onto that resource, the outcome in the absence of regulation is well-documented. It is the “tragedy of the commons”, in which individually rational behavior produces collectively irrational outcomes. Garrett Hardin identified the mechanism in 1968; Elinor Ostrom won the Nobel Prize in Economics in 2009 for demonstrating the governance conditions under which commons can be sustainably managed. The open source commons currently lacks those governance conditions. It has the access structure of a commons, free extraction by all, without the governance structure that prevents tragedy or abuse.
4.2 Why Voluntary Action Has Failed and Will Continue to Fail
The standard industry response to arguments for regulatory intervention is to appeal to the potential for voluntary self-regulation: the assertion that corporations, properly informed of the costs they are externalizing, will act in their long-term interest by contributing to the maintenance of the infrastructure they depend upon. There are two problems with this response. First, it has been tried and has demonstrably failed. Second, the structural conditions that produced that failure have gotten measurably worse.
GitHub Sponsors has operated for several years. The voluntary participation rate among open source users is approximately 0.001 per cent. The Open Source Pledge is a more recent initiative asking companies to commit a minimum of $2,000 per developer per year to open source. While it has attracted a small number of early adopters, predominantly smaller technology companies, it is not the hyperscalers whose AI tool deployment is the primary driver of the problem this paper addresses. These initiatives are not failures of design or communication. They are demonstrations that the collective action problem inherent in commons governance does not yield to voluntary mechanisms in the absence of either binding agreements or reputational incentives strong enough to overcome the financial benefit of free-riding.
The collective action problem takes a specific form here. Even a corporation that recognizes its dependency on open source maintenance and would, in isolation, prefer a well-maintained ecosystem to a deteriorating one has a strong competitive incentive not to contribute unilaterally. Every dollar spent on open source maintenance is a dollar not spent on competitive activities, and the benefit of that maintenance is shared equally with competitors who spend nothing. The only rational response under these conditions, for a firm maximizing its own competitive position, is to free-ride and hope that enough others contribute to keep the commons functioning. This is not bad faith! It is the predictable outcome of a measurement and incentive framework that rewards free-riding.
Mandatory contribution solves the collective action problem that voluntary mechanisms cannot, because it eliminates the competitive disadvantage of unilateral participation. When all commercial beneficiaries of the open source commons are required to contribute proportionately, no individual firm is penalized for contributing. The cost is distributed across the industry rather than borne disproportionately by the conscientious minority.
4.3 The Governmental Duty of Care
Governments have a specific obligation in this context that extends beyond general market regulation. Open source infrastructure is not merely a private sector resource. It underpins financial systems, healthcare networks, energy grid management, national defense capabilities, and public communications infrastructure. Its failure is not just a private sector problem. It is a national security risk of the first order.
The XZ-Utils near-miss in 2024 was a demonstration, in miniature, of what that failure looks like. A backdoor inserted through the social engineering of a single, overwhelmed volunteer maintainer came within a routine system update of compromising global SSH infrastructure. The attacker had nation-state level patience and sophistication. The defender had none: a single individual, unpaid, managing a critical library in personal time, with insufficient capacity to thoroughly scrutinise the contributions of a persistent and skilled adversary.
The OpenSSF and Georgetown CSET have both documented that AI dramatically lowers the cost and sophistication barrier for equivalent attacks. An attack that required multi-year human investment to execute in the XZ-Utils case can now be partially or substantially automated. The number of potential targets that a sophisticated attacker can pursue simultaneously increases in proportion to the automation available. The maintained volunteer community that is the primary defense against such attacks is shrinking, burning out, and now absorbing additional review burden from the AI tool adoption of commercial organizations.
The question for governments is not whether a systemic failure event is possible. Log4Shell and XZ-Utils have already demonstrated that it is. The question is at what point the expected value of the downside risk, the probability multiplied by magnitude of damage, exceeds the political cost of intervention. This paper argues that point was reached some time ago, and that generative AI has now compressed the timeline to the point where continued inaction represents not caution, but outright failure of the governmental duty of care.
Part 5: The Policy Gap — Existing Instruments and Their Limits
The argument for a Sovereign OSS Fund does not require that existing regulatory instruments have done nothing. Several have made meaningful contributions to the problem space. The argument is that collectively they leave a gap that is both large and consequential, and that the gap is precisely the one the fund is designed to fill.
5.1 What Exists
The EU Cyber Resilience Act (2024) is the most relevant existing instrument. It places mandatory security obligations on manufacturers of products with digital components, including products built substantially on open source foundations. In principle, it creates downstream liability for products that fail to meet defined security standards, establishing the precedent that commercial beneficiaries of open source have obligations that follow from that benefit. In practice, it creates compliance obligations but not maintenance funding: a manufacturer can satisfy its Cyber Resilience Act obligations by documenting its dependencies and implementing security response processes without contributing a single euro to the maintenance of the open source projects it depends upon.
The Biden administration’s 2021 Executive Order on Cybersecurity mandated Software Bills of Materials for government procurement, requiring federal contractors to document their open source dependencies. This created the disclosure infrastructure that a contribution obligation model would require: if commercial organizations are required to know and declare what they depend on, that declaration can become the basis for a proportionate contribution obligation. The SBOM mandate is the thin end of the wedge. It has not yet been extended to create the contribution obligation that its transparency would make administratively feasible.
The Biden National Cybersecurity Strategy (2023) shifted liability for insecure software toward organizations best positioned to reduce risk, explicitly rejecting the prevailing norm under which end users bear the cost of software vulnerabilities that developers or vendors could have prevented. The logic applies directly to the open source context: the organizations best positioned to reduce the risk of open source infrastructure failure are those large commercial entities with the resources to fund its maintenance. The strategy’s logic has not, however, been extended to create specific obligations in the open source maintenance context.
5.2 What Is Missing
The gap left by these instruments has three dimensions. First, none of them creates a funding mechanism. The Cyber Resilience Act creates compliance costs. The SBOM mandate creates disclosure costs. Neither generates resources for the maintenance it implicitly depends upon. Open source projects whose security and maintenance standards are assessed by the Act’s compliance framework will be judged against criteria that their volunteer maintainers have no additional resources to meet.
Second, none of them addresses the AI dimension specifically. The acceleration of the problem documented in the preceding sections, specifically the flood of AI-generated contributions, the novel attack vectors, and the systemic invisibility of costs to corporate ROI frameworks, is entirely outside the scope of instruments designed before widespread AI coding tool adoption.
Third, none of them addresses the governance problem. Who decides which projects are critical, and how are disbursements made against principled criteria rather than lobbying effectiveness? The absence of a credible, independent answer to this question is itself a barrier to the voluntary corporate contributions that the gap leaves as the only available mechanism. Corporations that might be willing to contribute do not have a trusted mechanism through which to do so that distributes the benefit to genuinely critical projects rather than high-profile ones.
The Policy Gap in Summary: Existing instruments create transparency obligations (SBOM mandates), compliance obligations (Cyber Resilience Act), and liability-shifting logic (2023 National Cybersecurity Strategy). None creates a funding mechanism, none addresses the AI dimension specifically, and none resolves the governance question of how to identify critical projects and distribute resources to them credibly and independently. The Sovereign OSS Fund fills all three gaps.
Section 6: The Sovereign OSS Fund — Architecture, Rationale, and Design
The Sovereign OSS Fund is the central policy proposal of this paper. It is designed to address the market failure described in the preceding sections by internalizing the costs currently externalized onto the open source commons, doing so in a manner that is proportionate to commercial benefit and AI deployment scale, transparent in its governance and disbursements, and independent of both government control and industry influence in its critical designation decisions. This section sets out the fund’s rationale, its contribution structure, and its governance architecture.
6.1 The Systemic Risk Insurance Framing
The most rigorous case for the fund rests not on the polluter pays principle alone, though that principle is sound and applicable. It focuses instead on the systemic risk insurance framing inherent in the open source software ecosystem. Critical open source infrastructure is a public good, it is non-excludable (anyone can access it), non-rivalrous (one party’s use does not reduce another’s), and subject to free-riding at scale. It is also exposed to low-probability, high-impact failure events whose costs would be distributed across the entire digital economy without regard to any individual organization’s contribution history. This is the exact structure that insurance markets exist to address.
Conventional insurance cannot function in this context, however, because the underlying asset is a commons. No single party owns or controls it, and no single party can be assigned the residual claimant status that insurance underwriting requires. The Sovereign OSS Fund therefore functions as a collective insurance pool, operated by an independent body, funded by proportionate mandatory contributions from commercial beneficiaries, and structured to maintain the designated assets against failure. The contribution obligation is the insurance premium. The designated projects whose maintenance the fund supports are the insured assets. The catastrophic failure events that the fund is designed to prevent, such as a Log4Shell-scale vulnerability in critical infrastructure, an XZ-Utils-style supply chain compromise of national security significance, or the accelerating abandonment of projects underpinning healthcare or financial system infrastructure, are the insured risks.
The case for placing AI companies at the center of the mandatory contribution mechanism is not simply that they are large and profitable, though they are. It is that they occupy a uniquely paradoxical position in the open source ecosystem. They are its most intensive beneficiaries and, through the market deployment of AI coding tools, among its most consequential current stressors. The AI industry’s dependence on open source is not historical or incidental, it is ongoing and structural. Production AI systems today run on open source inference infrastructure, are evaluated against open source benchmarks, are fine-tuned using open source tooling, and are deployed through open source serving frameworks. The value of every commercial AI product on the market today is partly a function of the open source commons from which it was built and on which it continues to depend. Against this, the contribution noise, maintainer burden, and security surface expansion that AI coding tools are generating in the open source ecosystem represents a transfer of cost from the AI industry onto the maintainer communities it has already extracted value from, without commensurate return. The AI deployment levy proposed in this paper is not an external imposition on a bystander industry. It is a contribution requirement on the industry that has extracted most from the commons and is now, measurably, making it harder to sustain. Framed correctly, and the framing matters for political viability, this is not regulation. It is the belated recognition of a debt.
This framing carries the urgency argument without alarmist leanings or hyperbole. The question put to governments is not whether catastrophic failure is possible. We are past that point, as it has already been demonstrated that it is. The question is whether the expected value of the downside risk now justifies the cost of collective insurance. The answer is yes, and it has been yes for some time. AI has not created this conclusion, it has made it more urgent and more undeniable.
6.2 The Polluter Pays Dimension
Alongside the insurance framing, the polluter pays principle provides the moral and legal foundation for the contribution obligation. Organizations that deploy AI coding tools at scale impose costs on the open source commons that their tools degrade. Those costs are real, measurable at the aggregate level, and uncompensated. The principle that the party generating an externality should bear the cost of it, established in environmental regulation across all major jurisdictions, cleanly and directly applies here.
The fund is not a tax, and the paper asserts this distinction explicitly and for structural rather than merely rhetorical reasons. A tax generates general government revenue allocated through the political budget process. The Sovereign OSS Fund contributions flow directly into a ring-fenced mechanism managed by an independent body outside direct government control, disbursed according to publicly auditable criteria to specifically designated projects. No government has discretionary access to fund proceeds. The contribution is tied to a defined public benefit, literally the maintenance of infrastructure from which the contributing organizations derives direct commercial value. It is kept equitable because it is proportionate to the scale of that benefit and the scale of the harm being generated.
6.3 The Contribution Tier Structure
The contribution structure is designed to satisfy proportionality and administrability simultaneously. A blunt mechanism that treats a ten-person startup identically to a hyperscaler would be both inequitable and politically unworkable. A mechanism so complex that compliance costs exceed contribution value would be administratively self-defeating. The four-tier model below achieves both requirements.
Tier 0 — Exempt:
Organizations with annual revenue below €10 million carry no contribution obligation. The administrative cost of collection from this tier would exceed the revenue generated, and the political cost of applying the mechanism to startups and early-stage companies would undermine its broader credibility. Voluntary participation is encouraged through an Open Source Pledge-style recognition scheme. This also ensures that it does not actively stifle the startup/early stage organization with regulation and cost that did not inhibit its predecessors.
Tier 1 — Base:
Organizations with annual revenue between €10 million and €500 million contribute at a flat rate scaled to their declared open source dependency footprint, as documented in mandatory SBOM disclosures. The existing EU Cyber Resilience Act and US Executive Order SBOM mandates provide the disclosure infrastructure this tier requires. Since organizations already have an obligation to know and declare what they depend on, that declaration becomes the basis for a modest proportionate contribution.
Tier 2 — Scaled:
Organizations with annual revenue above €500 million contribute at a rate that scales with both their revenue band and their declared AI coding tool deployment intensity. AI deployment intensity is measured by declared usage of AI coding tools above defined thresholds, and easily measured. Developer seat counts using AI assistants, AI tool spend above an auditable minimum, or where the data is available and technically feasible, the volume of AI-assisted commits above a defined level. This tier reflects the reality that larger organizations have deeper open source dependencies and are beginning to deploy AI tools at a scale that materially affects the ecosystem.
Tier 3 — Hyperscale:
Organizations with annual revenue above €5 billion, particularly those deploying AI coding tools at scale across tens of thousands of developers, carry the maximum contribution obligation. The weighting formula at this tier places the greatest emphasis on AI deployment intensity, on the basis that these organizations are the primary generators of the maintainer burden the fund exists to address. They are simultaneously the greatest extractors of value from the open source commons, the primary deployers of the tools degrading it, and the parties with the greatest capacity to contribute to its maintenance. The moral and financial case converges at the hyperscale tier.
6.4 The AI Deployment Levy
The AI deployment intensity metric at Tiers 2 and 3 is the most novel element of the contribution structure and the one most directly connected to the paper’s argument. A contribution obligation based solely on open source dependency footprint, which existing proposals such as the Open Source Pledge approximate, does not distinguish between organizations that are worsening the maintenance burden through AI deployment and those that are not. The AI deployment levy closes this gap.
The metric is imperfect, as all regulatory proxies are. AI coding tool usage is not uniformly distributed across development activities, and some AI-assisted contributions to open source are high quality and do not impose net costs. The metric measures deployment at scale rather than harm at the contribution level. That is because harm at the contribution level is not currently measurable. This is an acknowledged limitation that should be revisited as measurement capabilities develop. What the metric achieves is that the highest contribution obligations fall on the organizations whose AI deployment is most plausibly connected to the harm the fund is designed to mitigate. The hyperscalers and large SaaS companies deploying AI coding tools to tens of thousands of developers, that are generating the review burden that is burning out the maintainer community.
This is the element of the proposal that will attract the most scrutiny from AI vendors and large technology companies, we are direct about it. The industry argument will be that AI deployment and open source harm are not causally linked at the individual contribution level, and that a levy based on deployment intensity is therefore arbitrary. The response is that causal attribution at the individual contribution level is precisely what the externality structure prevents. The harm is diffused across the commons and cannot be traced to individual actors. The levy is calibrated to deployment scale as the best available proxy for aggregate contribution to the harm, in the same way that environmental levies are calibrated to production volume or emissions rather than to individually attributable harm events. The standard for regulatory proxy metrics is workability and proportionality, not perfect causal attribution.
6.5 Governance: The Independent Review Council
The governance architecture of the fund is the element the paper treats with the greatest prescriptiveness, because it is where the risk of failure is highest and where the consequences of failure are most damaging to the fund’s legitimacy. Two failure modes must be structurally prevented rather than merely discouraged:
capture by government, which would allow the fund’s resources to be diverted to politically convenient purposes rather than technically critical ones
capture by industry, which would allow well-resourced lobbying to shape criticality designations in favor of commercially convenient projects rather than genuinely critical ones.
The Independent Review Council is the mechanism by which both failure modes are structurally addressed. Its design rests on a foundational principle: neither a government nor a company should have unilateral authority over what is designated as critical infrastructure. The IRC holds sole decision-making power on criticality designation, and its independence from both sets of interests is structural.
The IRC is composed of technical experts drawn from the security research, open source maintainer, and software engineering communities; academic representatives with relevant expertise in software security and infrastructure governance; and civil society and digital rights organizations. No active corporate directors/officers/principals and no government officials serve on the IRC. Membership is selected through an open nomination process with mandatory conflict-of-interest disclosure requirements. Term limits prevent entrenchment. The full deliberation records of every designation decision are published on the Public Transparency Register.
The oversight structure above the IRC consists of a Statutory Framework Body, comprising government representatives from participating jurisdictions, which sets contribution obligation levels and provides the legal authority for the fund, but which has no operational authority over designation decisions or disbursements. Government participation is limited to non-voting observer seats on the Fund Operational Board. Industry participation is limited to a single, annually rotating non-voting observer seat. All operational authority rests with the IRC’s nominees on the Fund Operational Board.
The precedents for this governance model in the open source context are established and successful. The Internet Security Research Group, which operates Let’s Encrypt and provides free TLS certificates to the majority of websites globally, functions as a public benefit corporation with transparent governance that is neither government-controlled nor industry-dominated. The Linux Foundation hosts critical infrastructure projects under a neutral governance umbrella that has sustained significant projects across organizational and political changes. Neither is a perfect template, but both demonstrate that the independent governance model is achievable and has worked at scale in the open source context.
The fund’s designations, disbursements, and governance deliberations are all published in full on the Public Transparency Register, operated by an independent auditor appointed by the Statutory Framework Body. The register is not subject to modification by either government or industry participants. This transparency mechanism serves a dual purpose. It provides accountability for the IRC’s decisions, and it provides the public record that allows civil society, academic researchers, and affected communities to identify and challenge designation errors through the formal appeals process.
6.6 Criticality Designation: Methodology and Safeguards
The criticality designation methodology is designed to ground designation decisions in objective, publicly auditable criteria rather than political judgment. Three categories of evidence are assessed by the IRC for each designation decision.
Dependency and usage metrics provide the quantitative foundation: download volumes across major package managers, dependency graph depth and breadth, and contributor concentration. Projects dependent on fewer than five active maintainers are flagged for heightened scrutiny regardless of their current stability, on the basis that the risk is prospective. These metrics draw on existing public data sources including package manager APIs, the OpenSSF Security Scorecard, and the Linux Foundation Census methodology. They are not proprietary to the fund and are independently verifiable.
Infrastructure criticality assessment examines whether the project underpins systems in sectors formally designated as critical national infrastructure in participating jurisdictions: financial services, healthcare, defense supply chains, communications infrastructure, energy systems, and public administration. Projects that are material dependencies of systems in these sectors carry a different risk profile than projects of equivalent download volume in consumer applications, and that difference is reflected in the designation weighting.
Maintenance health assessment evaluates the current and projected adequacy of the project’s maintenance regime against the risk it represents. A project that is currently stable but whose maintainer community is declining, whose burnout indicators are elevated, or whose security response timelines are lengthening is a candidate for proactive designation rather than reactive response to failure.
All designation decisions are published in full, including the IRC’s reasoning, the data reviewed, dissenting views from IRC members, and the weighting applied to each assessment category. An appeals mechanism allows any organization to challenge a designation or non-designation through a panel drawn from outside the IRC membership. The appeals process does not give any single party veto power over designations; it provides a formal corrective for errors without creating a mechanism for strategic delay.
The Full IRC and Fund structure: It is impossible to fully detail and document all possible structural and procedural functions of the proposed organization, and indeed we would not want to. The basic formation, by non-profit incentivized parties is the limit of the structural recommendation. The expectation is that the first actions of the founding body itself would be to set up the norms, procedures, and overall structure of the governing body, and the fund. This would far exceed the abilities of the policy statement, but should not be seen as a deficiency. Self-governance is a critical part of open source, and the goal of the IRC is to protect, not determine, and so the proposal matches that ethos.
Section 7: Anticipated Objections and Responses
This section addresses the objections most likely to be raised against the Sovereign OSS Fund by industry stakeholders, policy sceptics, and critics of regulatory intervention. The paper addresses them here rather than in an appendix because anticipating and answering objections is part of the policy argument, not a supplement to it. A proposal that cannot survive rigorous scrutiny should not be recommended; one that can should demonstrate this directly.
7.1 ‘This is an AI tax by another name’
This is the most predictable political attack on the proposal and the paper is direct in response. The distinction between the Sovereign OSS Fund contribution and a tax is structural and legally significant. A tax is a compulsory payment to government generating revenue allocated through the political budget process, with no defined beneficiary and no hypothecation to a specific purpose. The Sovereign OSS Fund contribution is a compulsory payment to a ring-fenced mechanism managed by an independent body outside direct government control, disbursed against publicly auditable criteria to specifically designated beneficiaries, with no government discretion over the allocation. These are different instruments both in law and in economic function.
The contribution is better characterised as a mandatory insurance premium or a utility infrastructure levy: a defined payment into a collective mechanism that maintains shared infrastructure from which the paying party derives direct commercial benefit, scaled to the scale of that benefit. The political argument that this constitutes a tax on innovation is answered by the tier structure: a small company with minimal AI deployment pays nothing. A hyperscaler deploying AI coding tools to tens of thousands of developers, extracting billions of dollars in productivity value from open source infrastructure, and generating a proportionate share of the review burden degrading that infrastructure, pays a contribution commensurate with that footprint. Calling that contribution a tax on innovation inverts the actual relationship: it is the price of using innovation responsibly.
Objection: ‘You are penalising AI adoption and will stifle the industry.’: The proposal does not restrict AI adoption. It requires that organisations adopting AI at scale contribute proportionately to the maintenance of the infrastructure their tools are degrading. The Tier 0 exemption ensures that startups and early-stage companies are unaffected. The AI deployment intensity weighting ensures that the heaviest obligations fall on the parties with the greatest capacity to bear them and the greatest connection to the harm. The alternative — unrestricted AI deployment that continues to degrade critical infrastructure until a systemic failure event produces emergency remediation costs far exceeding any contribution obligation — is the outcome that stifles industry.
7.2 ‘Determining what is “critical” is too arbitrary and creates capture risk’
This is a legitimate governance challenge, and it is answered by the IRC architecture rather than dismissed. The response rests on three elements.
First, the designation methodology is objective and auditable. Criticality is assessed against quantifiable metrics drawn from publicly available data sources, not political judgment. The IRC’s reasoning for every designation decision is published in full. Any organisation can challenge a designation through a formal process. The arbitrariness risk is mitigated by methodology transparency; the capture risk is mitigated by governance structure.
Second, the IRC’s independence is structural. No corporate employees and no government officials sit on the IRC. Neither the government observer seats nor the industry observer seat on the Operational Board carry voting rights on designation decisions. The membership selection process requires conflict-of-interest disclosure and operates through open nomination. None of these safeguards is individually perfect; collectively they make undue influence visible and resistible rather than merely prohibited.
Third, the relevant comparison is not between the proposed IRC and a theoretically perfect independent body, but between the proposed IRC and the current situation: no governance, no accountability, no transparency, and de facto designation by default — where ‘criticality’ is determined entirely by whether a project’s failure has already caused enough damage to attract attention. The IRC is substantially more robust than the status quo, and the paper should make that comparison plainly rather than defending against a standard of perfection that no regulatory body meets.
7.3 – Objection – ‘Companies in jurisdictions that implement this will be competitively disadvantaged relative to those in jurisdictions that do not.’
The EU Cyber Resilience Act and GDPR have established that extraterritorial reach is achievable for digital regulation. Currently, any company serving EU customers or operating EU infrastructure is subject to EU rules regardless of its country of incorporation. The Sovereign OSS Fund would function on the same basis. Beyond jurisdictions, the systemic risk argument inverts the competitive disadvantage claim. A catastrophic failure in critical open source infrastructure damages all participants in the digital economy equally, regardless of jurisdiction, just as the software itself may be written in one jurisdiction and used in all. Collective maintenance of that infrastructure is not a competitive disadvantage – it removes the disadvantage outright form the voluntary structure that incentivizes free-riders. At this point it simply is a precondition for the market continuing to function at all.
7.4 – Objection – ‘Governments cannot be trusted to manage technology infrastructure’
The fund design anticipates this objection structurally. The government’s role is limited to:
setting the legal framework and contribution obligation levels through the Statutory Framework Body
providing annual public audit and parliamentary accountability
participating as a non-voting observer on the Fund Operational Board.
Governments do not designate critical projects, do not control disbursement decisions, and do not have discretionary access to fund proceeds. The operational authority of the fund resides entirely with the IRC and the Fund Operational Board, operating under independent governance charters with full public transparency.
The objection is a valid one if it were directed at a different model, one in which government directly administers the fund. That is not the model proposed. The proposed model is closer to the governance of Let’s Encrypt or the Linux Foundation’s hosted projects: public benefit, independent operation, transparent governance, government engagement limited to the legal framework and accountability oversight that any significant financial mechanism requires.
Conclusion: A Duty of Care for the Digital Commons
Open source software is infrastructure. It carries the same systemic importance to the digital economy that roads, power grids, and water systems carry to the physical one. We do not expect roads to be maintained by volunteers on the assumption that the drivers who use them will contribute freely. We do not leave the maintenance of power infrastructure to the discretion of the industrial consumers whose operations depend on it. We recognize that shared infrastructure requires shared governance and shared funding, and we build the regulatory and institutional frameworks that make that possible. The open source commons has been operating without those frameworks for two decades, sustained by a volunteer community whose goodwill is finite.
Generative AI has not created this problem. It has arrived at a moment of particular structural vulnerability and added a new category of load to a system already under severe strain. The response to that addition cannot be to ask the volunteers who have been carrying the weight to carry more. It cannot be to convene another industry round table on voluntary commitments. It cannot be to wait for the next Log4Shell or the next XZ-Utils attack that does not fail, to focus governmental attention. The cost of that wait, in economic damage, national security exposure, and the loss of the infrastructure itself, will be orders of magnitude greater than the cost of the intervention this paper proposes.
The Sovereign OSS Fund is a proportionate response to a documented market failure. It does not restrict AI. It does not punish innovation. It does not place government in control of the digital commons. It requires that the organizations that have built their commercial success on open source foundations, and that are now deploying tools that accelerate those foundations’ deterioration, bear a share of the cost of maintaining what they depend upon. It creates an independent governance body capable of making that determination credibly and transparently, insulated from both the lobbying power of industry and the political incentives of government. And it frames the contribution not as a penalty but as what it is: the collective insurance premium for an infrastructure risk that every participant in the digital economy shares.
Time’s up. The governance gap in the digital commons has been visible for years, and the evidence that it is worsening is now substantial. Governments that continue to defer to voluntary industry action on this question are not being cautious; they are being negligent. The tools to address it exist. The regulatory precedents exist. The governance model exists. What has been missing is the political will to use them. This paper is an argument that the moment for that will has arrived, and that the cost of waiting for a better moment will be measured in infrastructure we no longer have.
Bibliography — Working References
Note: References updated in v0.2 to reflect completed primary GHArchive research. References [1]–[3] expanded to full Tidelift series; references [27]–[28] are new additions.
[1] Tidelift. (2021). State of the Open Source Maintainer Report 2021. Tidelift Inc.
[2] Tidelift. (2023). State of the Open Source Maintainer Report 2022/23. Tidelift Inc.
[3] Tidelift. (2024). State of the Open Source Maintainer Report 2024. Tidelift Inc.
[4] Greenstein, S. & Nagle, F. (2024). The Value of Open Source Software. Harvard Business School Working Paper.
[5] Linux Foundation. (2024). Census II of Free and Open Source Software — Application Libraries. Linux Foundation / LABO.
[6] Xu, Z. et al. (2025). Predicting Open Source Project Abandonment on GitHub. arXiv preprint arXiv:2507.21678.
[7] Coelho, J. et al. (2019). GitHub Pull Requests Abandoned and Merged: A Large-Scale Study. arXiv preprint arXiv:1906.08058.
[8] GitHub. (2020). Octoverse 2020: The State of Open Source. GitHub Inc.
[9] GitHub. (2025). Octoverse 2025: The State of Open Source. GitHub Inc.
[10] GitClear. (2024). Coding on Copilot: 2023 Data Suggests Coding Assistants Degrading Code Quality. GitClear Research.
[11] Carnegie Mellon University. (2025). [Full citation pending primary source access.] Study of code quality degradation across 807 GitHub repositories adopting Cursor, 2024–2025.
[12] CodeRabbit. (2024–2025). [Full citation pending primary source access.] Analysis of AI-generated vs human-authored pull request issue rates.
[13] METR. (2025). Measuring the Impact of AI Coding Assistants on Developer Productivity: A Randomised Controlled Trial. METR Research.
[14] Atlassian. (2025). State of Developer Experience 2025. Atlassian Corporation.
[15] EY. (2025). Work Reimagined Survey 2025. Ernst & Young Global Limited.
[16] IBM Institute for Business Value / Morning Consult. (2024). AI ROI: From Potential to Profit. IBM Corporation.
[19] Georgetown CSET. (2024). AI-Enabled Supply Chain Attacks on Open Source Software. Center for Security and Emerging Technology.
[20] OpenSSF. (2024–2025). [Full citation pending primary source access.] Security guidance on AI and supply chain risk.
[21] Hardin, G. (1968). The Tragedy of the Commons. Science, 162(3859), 1243–1248.
[22] Ostrom, E. (1990). Governing the Commons: The Evolution of Institutions for Collective Action. Cambridge University Press.
[23] European Commission. (2024). Regulation (EU) 2024/2847 on horizontal cybersecurity requirements for products with digital elements (Cyber Resilience Act).
[24] Executive Office of the President. (2021). Executive Order 14028 on Improving the Nation’s Cybersecurity. The White House.
[25] The White House. (2023). National Cybersecurity Strategy. Office of the National Cyber Director.
[27] GHArchive / Google BigQuery. (2026). Primary analysis of open source contributor activity trends, 2015–2023. Original research conducted for this paper. Methodology and query documentation in supplementary materials.
[28] Raman, N., Cao, M., Tsvetkov, Y., Kästner, C., & Vasilescu, B. (2020). Stress and burnout in open source: Toward finding, understanding, and mitigating unhealthy interactions. Proceedings of the ACM/IEEE 42nd International Conference on Software Engineering: New Ideas and Emerging Results. https://doi.org/10.1145/3377816.3381732
Research Notes — Outstanding Actions for Further Research
Section 2 — Primary Research CompleteThe GHArchive BigQuery analysis has been completed covering 2015–2023 across a filtered set of high-longevity repositories. The 2024–2025 data will be incorporated in a subsequent revision. The forthcoming companion study tracking contributor migration versus exit is noted in Section 2.2 but is outside the scope of this paper.
• Extend GHArchive analysis to 2024–2025 to confirm post-2023 trajectory.
• Verify all quantitative figures from GHArchive primary research [27] against the supplementary data export before submission.
• Obtain full text of Carnegie Mellon Cursor study [11] and CodeRabbit analysis [12] for direct citation.
• Contact Xu et al. for year-disaggregated data from arXiv:2507.21678 as a cross-check against GHArchive primary findings.
• Systematic case study compilation: expand Section 2.4 to a minimum of 10 named projects with documented governance changes in response to AI contribution burden.
• Map EU Cyber Resilience Act SBOM obligations in detail to confirm they provide the dependency disclosure infrastructure the Tier 1 contribution model requires.
• Identify case law or regulatory precedents for hypothecated levies applied to digital infrastructure in EU and UK jurisdictions.
• Explore alignment of the critical infrastructure definition proposed in Section 6.6 with existing EU NIS2 Directive definitions and any divergences requiring explicit treatment.
• Develop the maintenance cost model for disbursement calculations in sufficient operational detail to be credible: what does it cost to maintain a critical project at the required standard, and what data sources underpin the estimate?
• Legal review of the IRC governance design: does the independence structure as proposed require specific treaty or statutory arrangements in the jurisdictions of intended implementation?
• Design primary research survey instrument for planned 2026 survey. Core questions: do you currently contribute to open source; have you reduced contributions over time; did you switch projects or stop entirely; what drove the decision. Design to be repeatable annually to build a longitudinal series comparable to the Tidelift survey line.